컬렉션 프레임워크를 구성하는 메인 인터페이스는 List, Set, Map 세 가지가 존재한다. 지금까지는 List와 컬렉션 프레임워크 존재 전에 사용했던 Vector에 대해서 알아보았는데, 이들은 중복 값 입력을 허용하며, 값이 저장된 순서도 유지한다는 특성이 있다. 이번 포스팅에서 살펴볼 HashSet과 TreeSet은 지금까지 살펴보았던 List와 달리 Set 인터페이스를 구현하는 클래스인데, 이들은 중복되는 값의 저장을 허용하지 않으며 저장 순서도 유지하지 않는다. 값의 중복을 허용하지 않기 때문에 데이터베이스(DB)에서 PrimaryKey 역할을 하는 값들의 저장에 많이 사용한다. 예를 들면 어느 기업의 직원 정보 중 사번이나, 회원 정보 중 회원 번호, 혹은 바로 다음 포스팅에서 다룰 Map 컬렉션 프레임워크의 Key와 같은 것을 들 수 있다.
HashSet과 TreeSet을 통해 Set의 특성과 사용법에 대해 알아보자.
1. HashSet 클래스
다른 컬렉션프레임워크 클래스와 마찬가지로 HashSet 역시 java.util 패키지 내에 존재한다. 생성자 역시 다른 컬렉션 프레임워크 클래스와 크게 다르지 않으나, 오버로딩으로 추가된 내용이 하나 더 존재한다.

HashSet에는 loadFactor라는 개념이 존재한다. HashSet을 구성하는 요소의 수가 기존에 설정한 HashSet의 크기를 일정 기준 이상 초과하면 크기를 증가시키게 되어 있는데, loadFactor는 이 기준을 정해준다. 만약, capacity(크기)가 10이고, loadFactor가 0.75라면, 8개의 요소가 HashSet에 저장되는 순간 Capacity가 증가한다. HashSet에서 직접적으로 capacity를 확인할 수 있는 방법은 없으니, 이런 방법으로 크기를 조절한다라고 이해만 하면 된다.
값의 추가와 삭제는 다른 컬렉션 프레임워크와 동일하게 Collection 인터페이스에 정의된 add(), remove() 메서드를 사용한다.

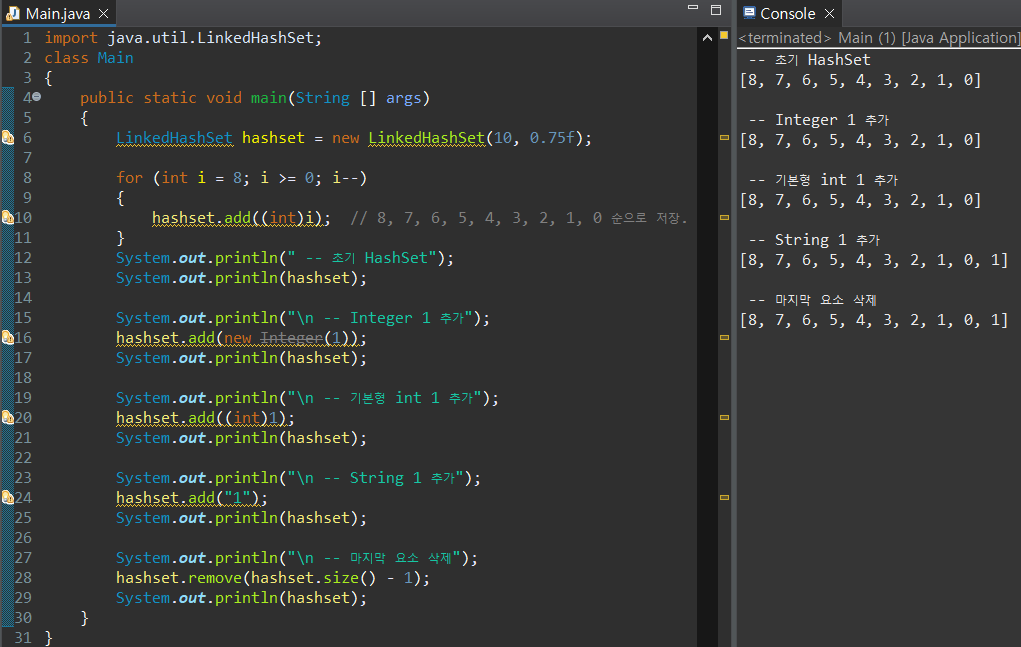
위의 결과를 보면 흥미로운 사실이 하나 확인되는데, Set의 경우 데이터의 순서가 뒤죽박죽이더라도 기본적으로 오름차순 정렬을 내부적으로 진행한다는 것이다. 필자의 경우 위의 예시에서 데이터 입력을 8부터 역순으로 0까지 진행했는데, sort()와 같은 정렬 매서드가 HashSet 클래스 내에 부재함에도 불구하고 자동으로 오름차순 정렬이 된다.
또한 중복된 값을 추가하는 부분 역시 (Integer 1 및 int 1 추가), 기존에 HashSet 내에 존재하는 1과 중복되는 값이라 HashSet에 추가가 되지 않음을 확인할 수 있다. HashSet.add() 매서드는 매개 변수 값을 HashSet 내에 저장하기 전에, Object.equals()와 Object.hashCode() 함수를 통해 HashSet 내에 동일한 값이 존재하는지 확인한다. 만약 값이 존재한다면 false를 반환하고, 그렇지 않으면 true 반환 및 값을 HashSet 내에 저장한다.
따라서 파일의 세 번 째 문단을 보면 String "1" 값을 추가한 코드가 보이는데, 이 코드는 문자열 "1"을 HashSet에 무리없이 저장한다. 기존에 HashSet에 존재하는 1은 정수형이고 추가값이 String이므로 당연히 equals() 매서드부터가 반환값이 false기 때문이다.
그럼, 이 경우는 어떻게 해야할까?
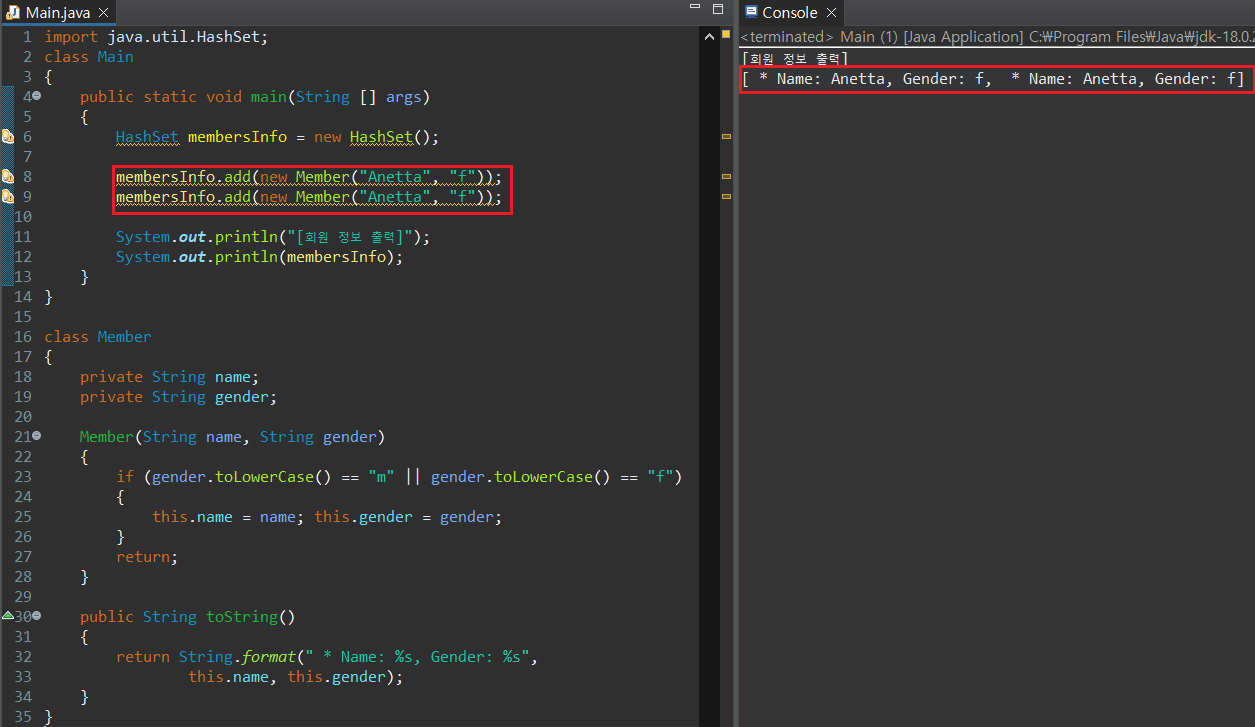
회원 정보로 입력한 Member의 인스턴스가 서로 다른 메모리를 가리켜, 동일한 내용을 가짐에도 불구하고 중복으로 판단되지 않은 상황이다. 바로 직전에 언급한대로, Set은 추가할 값과 기존의 값을 Object.equals()와 Object.hashCode()로 비교하기 때문에 Member에서 equals(), hashCode() 매서드에 대해 오버라이딩을 진행해주어야 한다.

hashCode()의 경우 함수의 특성에 따라 서로 다른 값이라도 동일한 결과가 나타날 수 있다. 따라서 hashCode() 뿐만 아니라 equals() 매서드도 함께 오버라이딩을 하는 것이 안정적이다. 위의 예시에서 equals의 경우 단순히 참조 객체의 메모리 주소를 참조하여 비교하는 것이 아니라, 마치 deepEquals()와 비슷하게 객체 내 값의 비교를 진행하도록 만들었다. 따라서 서로 다른 메모리에 올리온 Member 객체더라도, HashSet에서는 오버라이딩 된 equals()를 통해 두 인스턴스 객체가 동일한 값이라고 판단하게 되는 것이다.
중복값을 다루면서도 저장 순서가 중요한 경우라면(8부터 0으로 역순 출력이 되어야 한다면) HashSet이 아닌 LinkedHashSet 클래스를 인스턴스화하여 사용해야한다. LinkedHashSet 역시 HashSet과 마찬가지로 Set 인터페이스에 속하며 기능상의 차이는 거의 없기 때문에 사용 가능한 매서드를 HashSet과 공유한다.
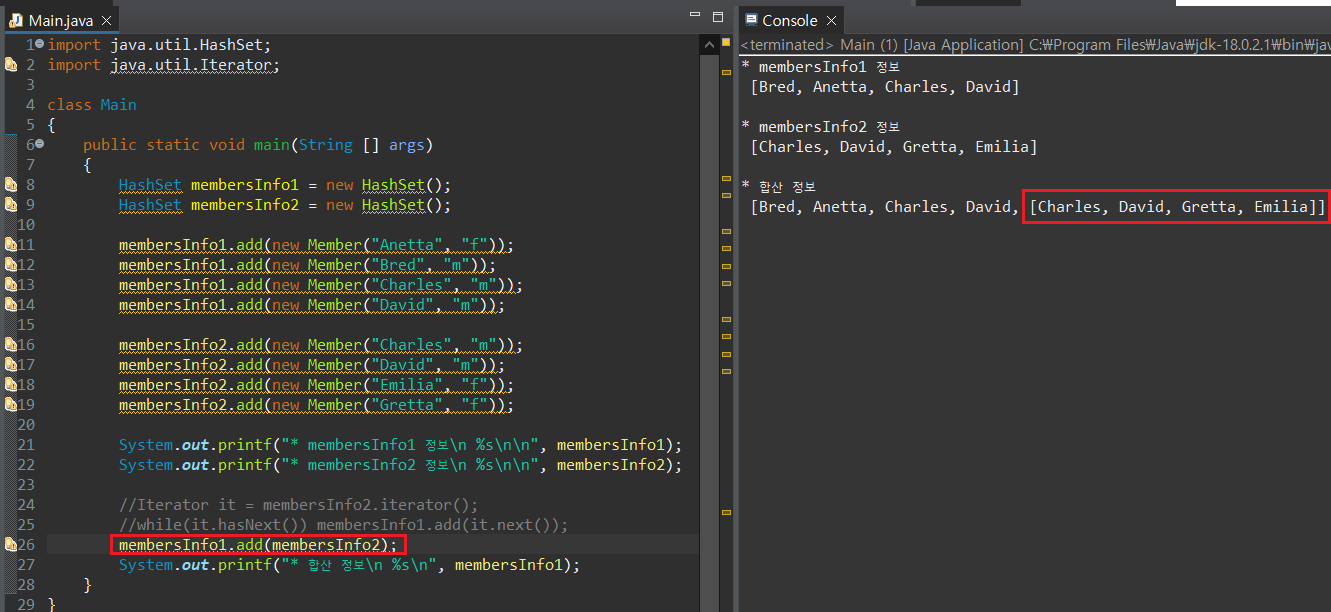
중복값을 허용하지 않는다는 특성으로 인해, 동일한 성격을 가지는 두 데이터를 합산해야하는 경우 많이 사용된다. 예를 들어, 위의 멤버 정보를 저장하는 인스턴스가 2개일 때, 중복되는 정보를 자동으로 삭제하면서 합산한다고 가정해보자.

별도의 메서드를 정의하지 않고 HashSet을 사용함으로써 두 데이터의 중복값을 제외한 합산이 마무리되는 것을 확인할 수 있다. 위의 예시에서는 membersInfo2를 add() 매서드로 통째로 넣지 않고 Iterator를 사용했는데, add() 매서드로 Collection 자체를 추가하는 경우, Collection 형태로 전체 내용이 추가되기 때문에 원하는 결과가 나타나지 않게 된다.
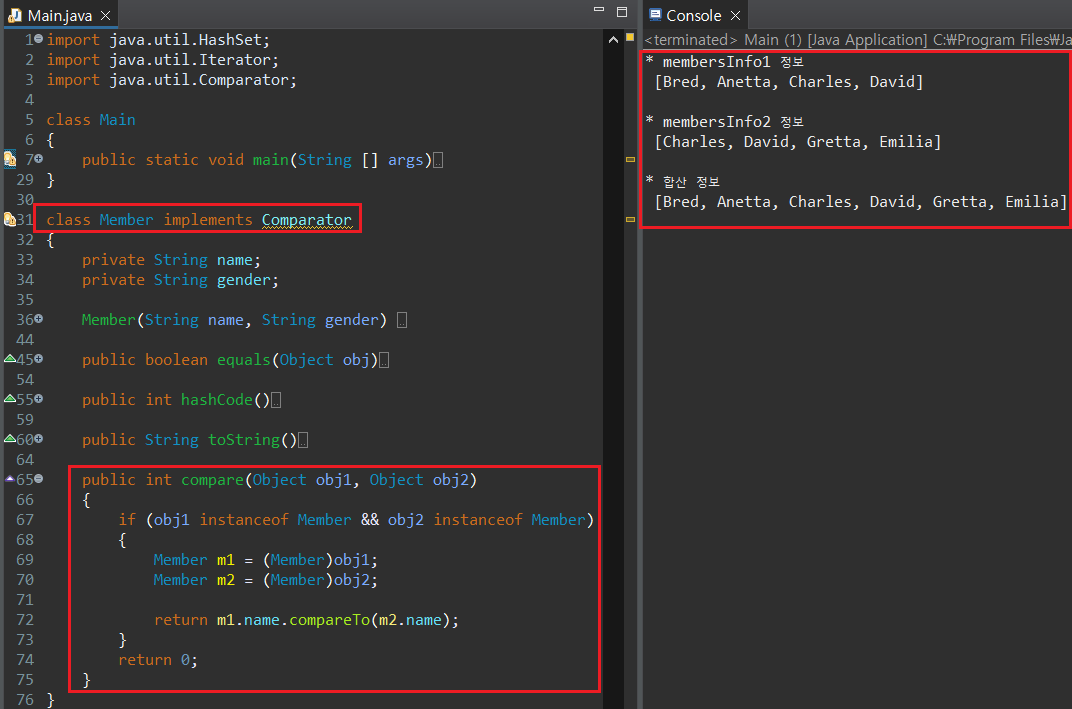
필자가 작성한 코드의 결과에서 멤버의 이름 정보가 알파벳 순으로 등장하지 않는데, 이는 참조 객체의 메모리 주소를 오름차순으로 정렬했기 때문이다. 만약 알파벳 순서로 회원 정보를 정렬하고 싶다면 Comparator 인터페이스를 Member에 구현하고 compare() 매서드를 정의해주어야 한다.
2. TreeSet 클래스
TreeSet 클래스는 Set 인터페이스에 속하는 클래스로 LinkedList와 같이 각 요소들이 연결되어(Linked) 있는 형태를 띈다.
따라서 다른 컬렉션 프레임워크와 달리, 저장된 값을 요소(Element)라고 부르지 않고 노드(Node)라고 부른다. TreeSet은 자료 구조 중 이진 검색(Binary Search)을 사용하여 이진 검색 트리(Binary Search Tree)로 분류되는데, 이러한 특성으로 인해 범위 내 자료 검색이나 정렬 시 매우 효율적이다. 다만 값을 추가하거나 삭제하는 과정은 LinkedList와 달리 시간이 걸리는 편인데, 트리 구조의 특성 상 구조 일부를 제구성해야하며, 배열 형태가 아니기 때문에 위치를 선정하는 것도 쉽지 않기 때문이다.
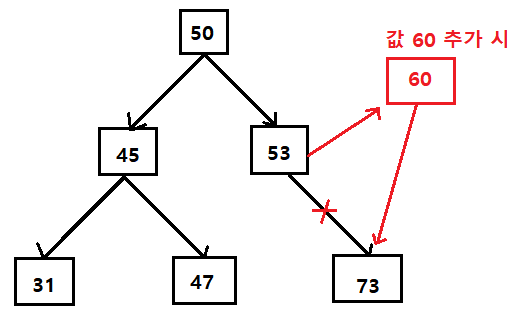
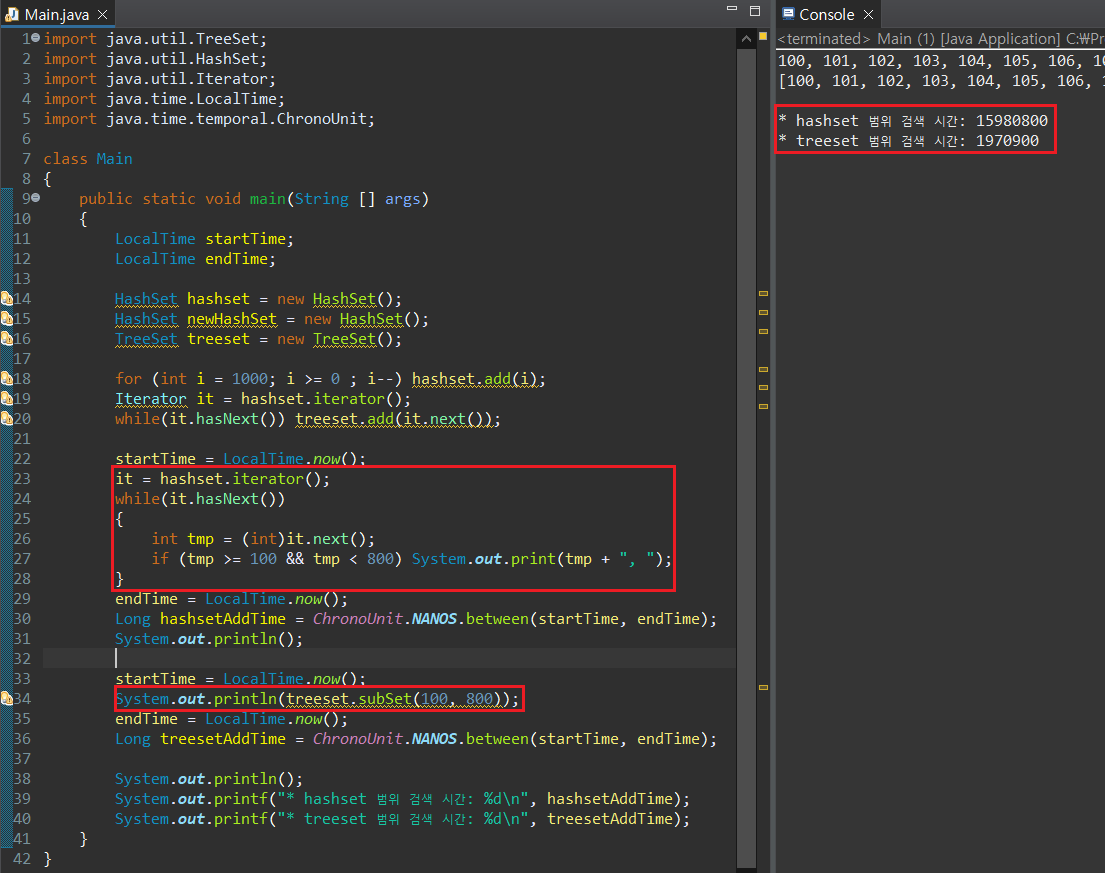
HashSet과 TreeSet의 인스턴스를 동일하게 생성하고, 값을 삭제하는 과정에 걸린 시간을 측정해보자.

시간 단위는 나노초(10^(-9)) 단위인데, 이 범위에서 treeset이 값을 추가하고 삭제하는데 있어 hashset보다 효율적이지 못함을 확인할 수 있다.
대신 값을 검색하는 것은 HashSet에 비해 매우 빠를 수 밖에 없는데, HashSet이 순차적으로 모든 요소를 훑어 들어와야하는 반면, TreeSet은 최상단의 노드에서 찾고자 하는 값의 크기에 따라 1/2 확률로 자식노드로 이동하며 값을 비교하면 되기 때문이다. 따라서 TreeSet은 HashSet에 비해 검색 시간이 최대 절반까지 줄어드는 효과가 있다.
특정 범위 내의 값을 추출하여 출력하는 것 역시 구조적인 이유로 TreeSet이 HashSet보다 빠르게 진행된다.
TreeSet 역시 Collections 인터페이스에 정의된 모든 매서드를 사용할 수 있으며, TreeSet의 특성 상 몇 개의 추가 매서드가 정의되어 있다.

특정 값의 포함 여부는 contains() 외에도 celing()과 floor()로도 확인이 가능한데, contains() 매서드가 단순히 값의 포함 여부를 boolean으로 반환하는 것과 달리 ceiling(), floor()는 검색 값이 존재하면 그 값을 반환한다. 만약 값이 존재하지 않는다면 Ceiling()은 오름차순의 노드 값을, floor()는 내림차순 위치의 노드 값을 반환한다.
특정 노드의 값보다 작거나, 큰 값만 SortedSet 객체 타입으로 반환하는 것도 가능한데 이 역할을 하는 매서드가 headSet과 tailSet()이다. headSet()은 내림차순 방향에 위치한 노드 값을 SortedSet 형태로 반환하며, tailSet()은 반대로 오름차순 방향에 위치한 노드 값을 SortedSet 형태로 반환한다.

다음 포스팅에서는 컬렉션 프레임워크의 마지막 인터페이스인 Map과 하위 클래스에 대해 알아보려 한다.
Fin.
'Java > Java Basic' 카테고리의 다른 글
| [Java Basic] 38 - 컬렉션 프레임워크8 (java.util.Collections) (0) | 2022.09.07 |
|---|---|
| [Java Basic] 37 - 컬렉션 프레임워크7 (HashMap, TreeMap, Properties) (0) | 2022.09.07 |
| [Java Basic] 35 - 컬렉션 프레임워크5 (Arrays, Comparable, Comparator) (0) | 2022.09.05 |
| [Java Basic] 34 - 컬렉션 프레임워크4 (Iterator, ListIterator, Enumeration) (0) | 2022.09.02 |
| [Java Basic] 33 - 컬렉션 프레임워크3 (Stack, Queue) (0) | 2022.09.01 |




댓글