** 시작하기 전에, Java에서 Stream이라는 용어는 java.util.stream 패키지에 정의된 Stream 클래스에 대한 내용과, 입출력 관련 Stream 두 가지 의미를 가진다. Stream 클래스가 이번 포스팅에서 다룰 내용이며, 입출력 Stream은 다음 또는 다다음 포스팅에서 다룰 예정이다.
배열과 ArrayList, Queue를 하나씩 만들고 이들이 가진 요소값을 출력하는 코드를 만들어보자.

Queue와 ArrayList 등 Collection과 배열은 일부 기능을 제외한다면 차이가 거의 없다. 그러나 동일한 기능을 하는 매서드들을 호출해보더라도 이들의 이름이 달라 사용할 때마다 Java Documentation을 뒤적거려야하는 불편함은 여전히 존재한다. 예를 들어 필자가 List에 숫자 하나를 추가하기 위해서는 add() 매서드를 호출하면 되지만 Queue는 offer()라는 매서드를, 문자 배열을 다루는 StringBuffer는 append()라는 매서드를 사용해야한다. 위의 예시만 보더라도 요소 출력을 위해 배열은 index 번호를 적용해서, List는 get() 매서드로, Queue는 poll() 매서드로 값을 하나씩 추출하여 출력하는 것을 확인할 수 있다.
Eclipse와 같은 IDE 없이 이걸 다 기억할 수 있을까? 절대 못한다. 업무를 하면서 배열과 Collection 만을 다룬다면 어떻게든지 외우겠지만, 사실상 그렇게 일하는 프로그래머들은 없을테니까. 그럼, 게으르면서 머리가 잘 돌아가는 프로그래머들은 이를 타계할 방법을 생각할 것이다. 이거 하나로 묶어서 사용할 방법이 없을까? 여기서 파생된 개념이 Stream이다.
1. java.util.stream.Stream 클래스
Stream 클래스는 java.util.stream 패키지 내에 정의되어 있다. Java Documentation에 서술된 이 패키지의 내용을 살펴보면 Stream의 존재 목적이 첫 줄에 아주 명확하게 나와있다.
즉, 요소를 가지는 타입들에 대해 함수형 스타일, 람다식의 연산을 제공하기 위한 목적으로 만들어진 패키지다. 다시 말하면, 배열과 같이 요소를 가지는 타입에 대해 람다식을 적용하여 배열과 유사한(array-like) 타입을 조금 더 쉽게 다루기 위함이다.
Documentation 예시를 보자. widgets이라는 객체의 요소로부터 color 변수가 RED인 요소만 추출한 뒤, 해당 요소의 Weight값을 합산하는 과정을 하나의 식으로 정의했다. Stream과 람다식 없이 이 과정을 수행한다고하면 코드창이 if-else 문으로 떡칠이 될 것이 너무 명확해보인다.
그럼, java.util.stream 패키지에는 어떤 클래스가 있을까?
종류가 약간 많은데, 중요하게 봐야할 부분은 Stream이다. Stream이 이름에 포함된 나머지 클래스들도 잘 보면 알겠지만 Strema 앞에 Int, Double, Long 등의 Wrapper 타입이 붙은 것이라 기능 상에는 큰 차이가 없다.
2. Stream 객체의 생성
위에서 나타낸 예시와 같이, 배열의 형태를 띄는 모든 타입은 Stream 객체로 변환이 가능하다. 우선 Collection에 속한 타입들은 stream() 이라는 매서드를 사용하여, 배열 타입은 Stream 클래스에서 제공하는 static 매서드인 of()를 사용하여 Stream 객체로 변환할 수 있다. 크게 어렵지 않다.
* 배열의 stream 변환: Stream.of(배열 변수명);
* Collections의 Stream 변환: Collection_타입변수.stream();
배열과 유사한 타입을 Stream이라는 클래스에 종속시킴으로써, 서로 다른 타입의, 다른 이름을 가진, 같은 기능을
하는 매서드를 Stream 매서드로 손쉽게 처리할 수 있다.
배열 외에도 특정 범위 내의 숫자를 Stream으로 생성하는 것 역시 가능하다. 앞서 잠깐 소개했던 IntStream, DoubleStream, LongStream 등 숫자를 다루는 Stream은 별개의 클래스로 따로 정의되어 있는데, 이 클래스의 객체의 생성은 기존 배열을 활용하는 of() 매서드 외에도 몇 가지 방법이 더 있다.
[ 특정 범위 내 숫자를 Stream 요소로 무한히 생성]
* IntStream.range(int startNum, int limitNum)
* DoubleStream.range(double startNum, double limitNum)
* LongStream.range(long startNum, long limitNum)
* IntStream.rangeClosed(int startNum, int limitNum)
* DoubleStream.rangeClosed(double startNum, double limitNum)
* LongStream.rangeClosed(long startNum, long limitNum)
* Closed() 매서드는 limitNum를 포함함.
[ 무작위 숫자를 Stream 요소로 무한히 생성 ]
* Random.ints()
* Random.doubles()
* Random.longs();
* java.util.Random 클래스
[ 특정 범위 내 숫자를 Stream 요소로 제한적 생산 ]
* IntStream.range(int size, int startNum, int limitNum)
* DoubleStream.range(int size, double startNum, double limitNum)
* LongStream.range(int size, sizelong startNum, long limitNum)
* IntStream.rangeClosed(int size, int startNum, int limitNum)
* DoubleStream.rangeClosed(int size, double startNum, double limitNum)
* LongStream.rangeClosed(int size, long startNum, long limitNum)
* Closed() 매서드는 limitNum를 포함함.
[ 무작위 숫자를 Stream 요소로 제한적 생성 ]
* Random.ints(int size)
* Random.doubles(int size)
* Random.longs(int size)
* java.util.Random 클래스
숫자와 관련된 Stream이 별개의 클래스로 정의된 것은 다른 이유가 아니라, 평균, 총합, 최대, 최소 등을 구하기 위한 매서드를 정의해야하기 때문이다.
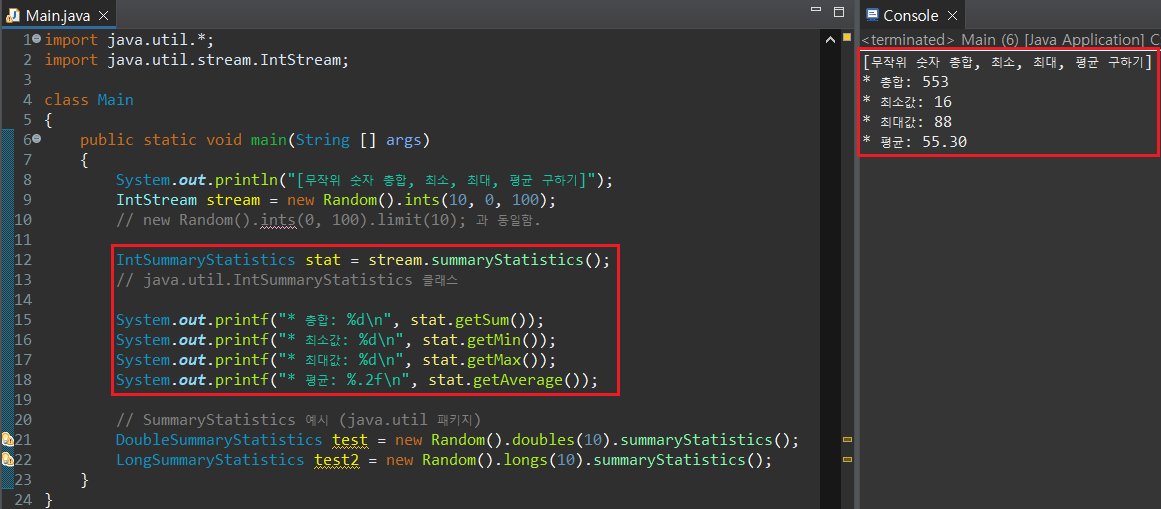
다만, IntStream, DoubleStream, LongStream 등은 최종 연산인 sum(), average(), min(), max()를 사용하는 순간 Stream이 소멸되어 재활용이 불가능하다. 따라서 java.util 패키지 내에 존재하는 IntSummaryStatistics, DoubleSummaryStatistics, LongSummaryStatistics 라는 객체로 Stream 정보를 저장하고, SummaryStatistics 계열 클래스의 매서드를 통해 총합, 평균, 최대/최소값을 반환받을 수 있다.
Stream 클래스에서 제공하는 iterate() 및 generate() 매서드를 활용하면 일반 람다식을 Stream 객체로 생성하는 것이 가능하다. iterate()와 generate는 람다식을 매개변수로 받아들이는데, 매개변수를 무한히 수행하며 나타난 결과를 요소로 Stream에 저장한다.
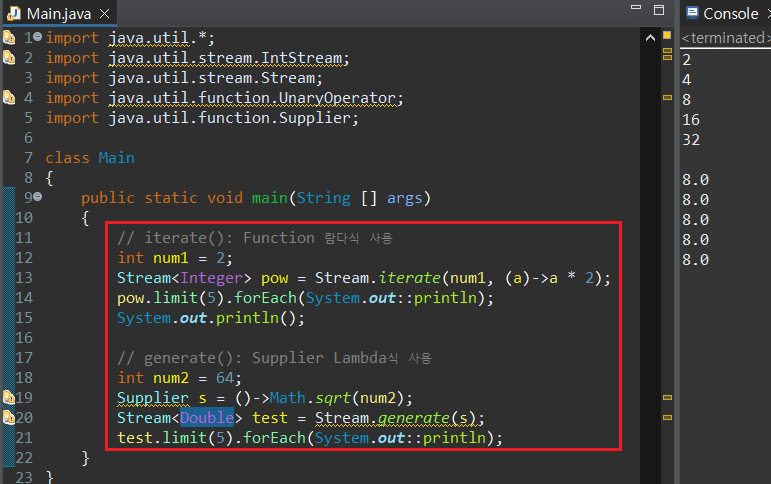
iterate는 Function 람다식을, generate는 Supplier 람다식을 사용한다. 따라서 iterate() 매서드는 Function 람다식의 입력값을 첫 매개변수로 받고(T Seed), 두 번 째 매개변수로 Function 객체(Function<T, R> f)를 받는다. Supplier는 입력 매개변수가 필요없기 때문에 generate 역시 람다식만 매개변수로 받는다.
이 외에도 특정 폴더의 파일을 추출하여 Stream으로 생성하는 방법도 있지만, 이 부분은 추후 입출력 Stream과 파일을 다루는 내용을 포스팅할 때 다시 언급하려 한다.
3. Stream의 매서드 분류 및 연산 특징
그럼 본격적으로 Stream 클래스의 매서드에 대해 알아보자. Stream 클래스의 특성 상 매서드 종류가 꽤 많은 편인데, Stream 클래스에서는 이들 매서드 분류를 Stream 타입으로 객체를 반환하는가 아닌가로 1차적인 분류를 하게 된다.

Stream 객체를 반환하는 매서드는 중간 연산(Statefule Intermediate Operation) 매서드라고 하며, 그렇지 않은 매서드를 최종 연산(Terminal Operation) 매서드라고 한다. Stream은 연산이 진행되면 생성된 Stream이 사라지게 되는데, 중간 연산의 경우, 연산 결과를 Stream 형태로 반환하기 때문에 여러 중간 연산 매서드를 중첩하여 사용하는 것이 허용되지만, 최종 연산 매서드는 생성된 Stream마다 단 한 번 만 사용이 허용된다.
예시를 보자. 필자는 임의의 6개 숫자가 나열된 ArrayList를 정렬하고(중간 연산), 이들의 정렬 결과를 출력하는(최종 연산) 절차를 Stream 매서드로 만들어보려한다.
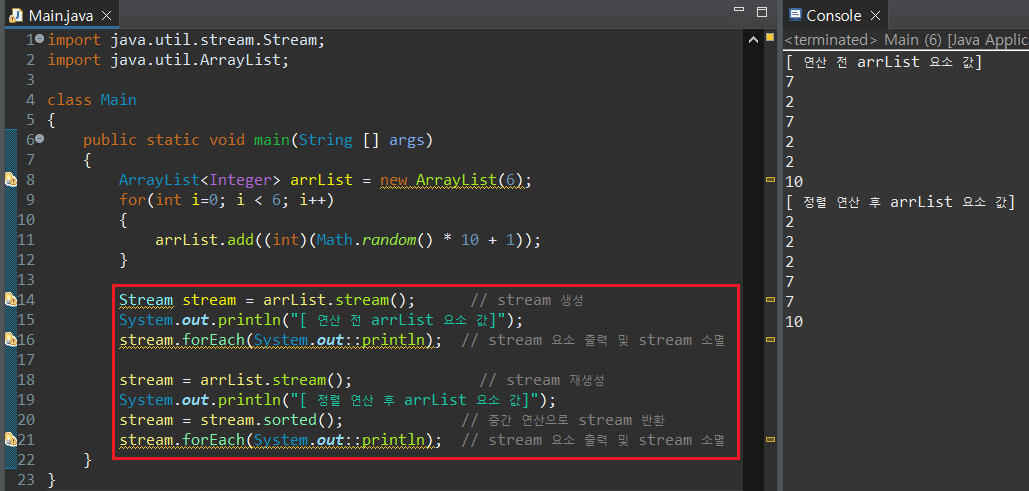
정렬 연산을 진행하기 전(sorted()), stream을 다시 재생성한 것이 보이는데, 처음 forEach() 문이 호출되었을 때, 생성한 stream이 소멸되기 때문이다. 만약 두 번 째 stream 선언 없이 코드를 실행하면 다음과 같이 에러가 나타난다.
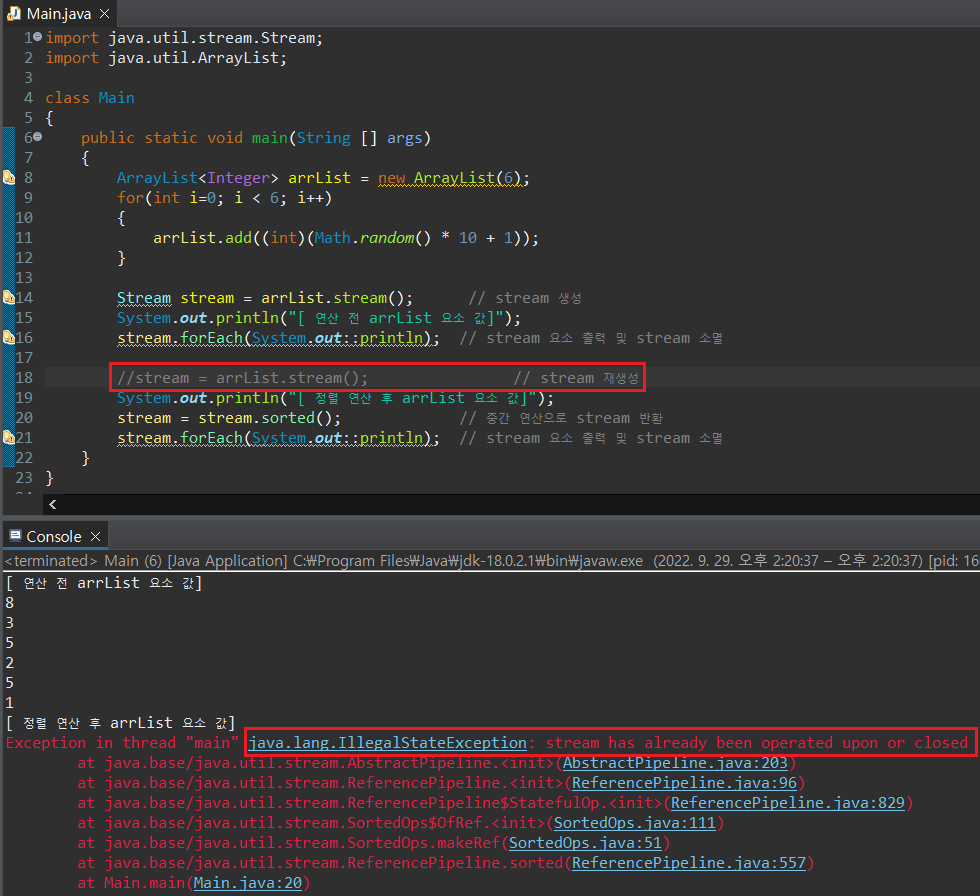
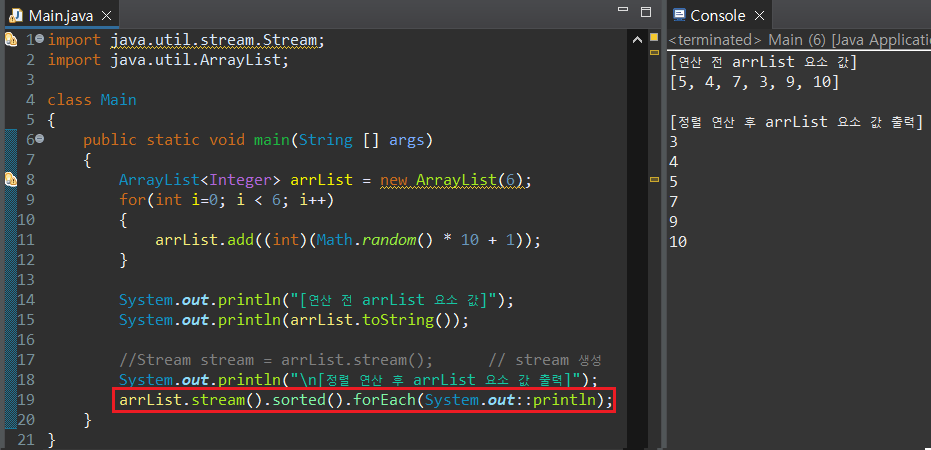
중간 연산인 sorted()도 마찬가진데, 결과값을 Stream 객체 변수에 저장하지 않는다면 동일한 에러가 발생한다. 따라서 sorted() 연산 결과를 stream으로 다시 저장할 수 있도록 코드를 넣은 것이다. 위의 코드를 하나의 식으로 변경하면 아래와 같이 나타낼 수 있다.
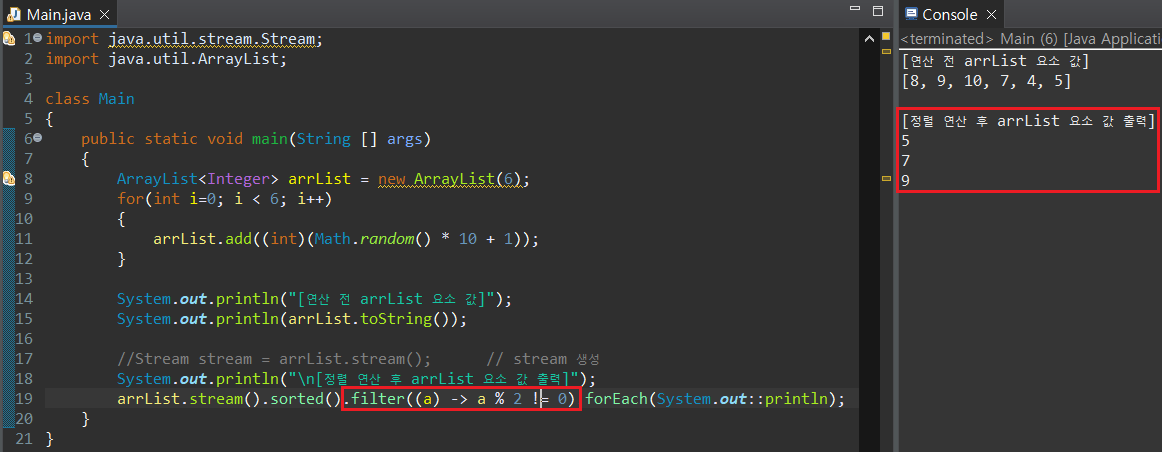
만약 짝수값만 출력하고 싶다면 filter() 매서드를 사용하여 중간 연산을 추가할 수 있다(자세한 사용법은 뒤에서 알아본다).
그럼 Stream에서 제공하는 중간 연산 매서드와 최종 연산 매서드에는 무엇이 있는지 알아보자.
[ 중간 연산 매서드 ]
* concat(Stream a , Stream b) : Stream a, b를 하나의 Stream으로 통합 후 반환
* distinct() : Stream 요소의 중복 제거 후 Stream 반환
* dropWhile(Predicate p) : Stream이 정렬된 상태인 경우, 첫 요소가 Predicate 조건과 일치하지 않으면 전체 요소를 Stream으로 반환. 그렇지 않은 경우 연속으로 조건을 만족하는 요소를 모두 삭제 후 남은 요소를 Stream으로 반환.
* empty() : 빈 Stream으로 반환.
* filter(Predicate p) : Stream 내 요소 중 Predicate 조건을 만족하는 요소만 추출하여 Streamd으로 반환.
* limit(int length) : Stream 요소 중 index 0~length -1 만큼만 추출하여 Stream으로 반환.
* peek(Consumer consume) : Stream 각 요소에 대해 Consumer 람다식 연산 진행 후 Stream으로 반환.
(Stream을 소모하지 않기 때문에 연산의 중간 결과 출력에 많이 사용함)
* skip(int length) : Stream 요소 중 index length ~ 만큼만 추출하여 Stream으로 반환.
* sorted() : Stream 요소의 기본값 정렬 후 Stream 반환.
* sorted(Comparator c) : Comparator에 구현된 조건대로 Stream 요소를 정렬하여 Stream으로 반환함.
* takeWhile(Predicate p) : Stream이 정렬된 상태인 경우, 첫 요소가 Predicate 조건과 일치하지 않으면 전체 요소를 Stream으로 반환. 그렇지 않은 경우 연속으로 Predicate 조건을 만족하는 요소만 Stream으로 반환. dropWhile()과 반대 기능을 함.
[ 최종 연산 매서드 ]
* allMatch(Predciate p) : Stream 내 모든 요소가 Predicate 조건을 만족하면 true 반환.
* anyMatch(Predicate p) : Stream 내 요소 중 하나라도 Predicate 조건을 만족하면 true 반환. Stream은 조건을 만족하는 첫 요소만 반환됨.
* noneMatch(Predicate p) : Stream 내 모든 요소가 Predicate 조건을 만족하지 않으면 true 반환.
* count() : Stream 요소 수를 정수형으로 반환
* forEach(Consumer consume) : Stream 내 요소에 대해 Consumer 연산 진행
* toArray() : 연산 결과의 Stream을 배열로 반환
* toList() : 연산 결과의 Stream을 List로 반환
사용법은 Documentation을 참고한다면 크게 어렵지 않으니, 사용 상 주의사항과 몇 가지 중간 연산 매서드만 추가로 설명을 진행하려 한다.
Stream 연산에 있어서 하나 주의해야 할 점이 있는데, 중간 연산 매서드만 나열하는 것으로는 어떠한 Stream 연산도 진행되지 않는다는 것이다. 예를 들어 필자가 중간 연산자인 peek()을 사용하여 Stream 내 요소를 삭제하면서, 다른 List 내에 추가(즉, Stream 요소를 LIst로 이동)한다고 해보자.
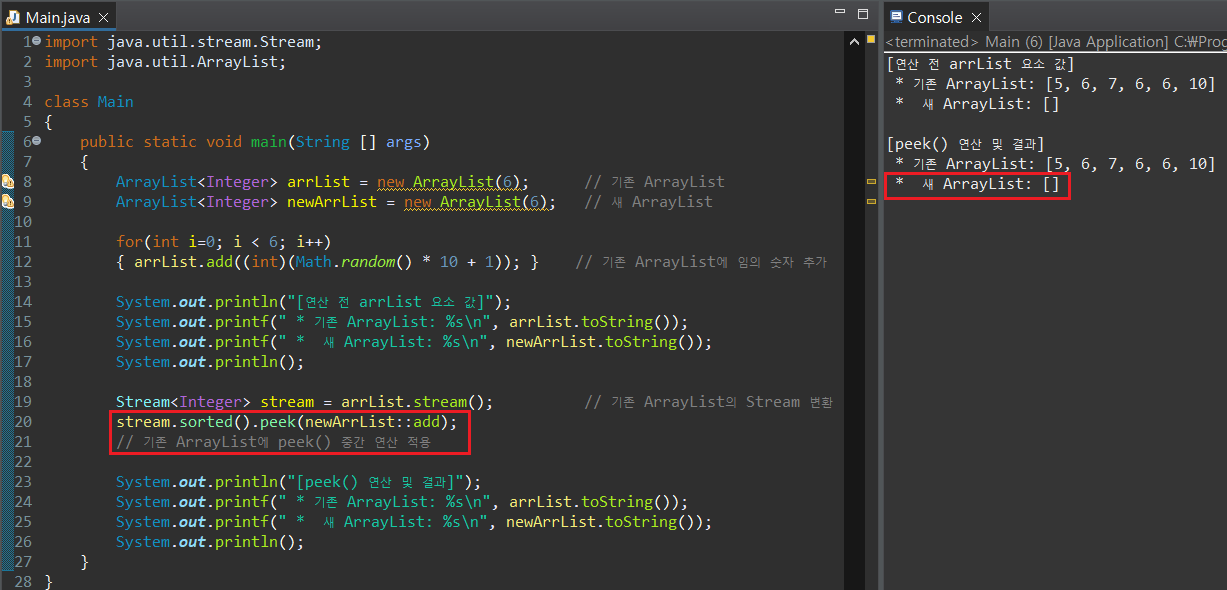
중간 연산을 통해 새 ArrayList에 Stream 요소 값을 이동시키려 했지만, 의외로 newArrList에는 값이 추가되지 않은 것으로 확인된다. Stream 연산의 경우, 최종 연산자가 실행되어야만 중간 연산도 진행되기 때문에 발생하는 문제다. 즉, 중간 연산 매서드가 개별적으로 작동하는 것이 아니라, 함수형 인터페이스가 합성되어 동작하듯이 연산이 이루어지기 때문이다.
필자가 중간 연산 코드 뒤에 최종 연산 매서드를 하나 붙이는 순간 필자가 의도한대로 결과가 나타남을 확인할 수 있다.
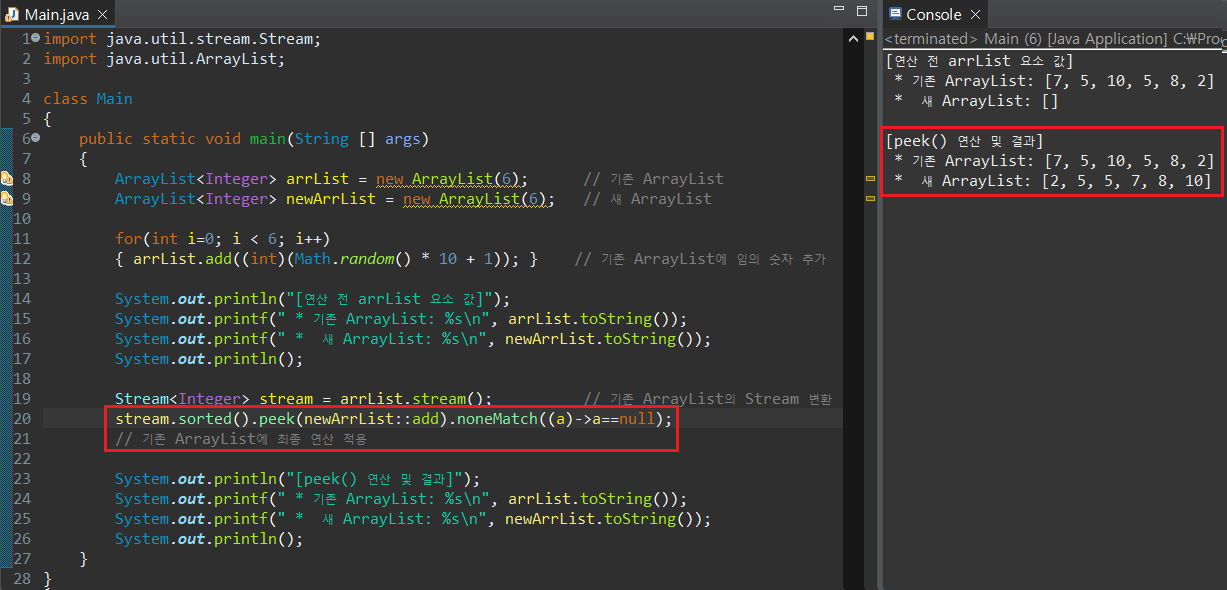
최종 연산인 noneMatch()를 만족하는 요소에 대해 peek 연산도 진행되기 때문에 새 ArrayList에 값이 추가될 수 있게 된다.
(1) sorted()
sorted()는 미리 정의된 방식으로 Stream의 각 요소를 비교하여 정렬하는데 사용하는 매서드다. 아무 매개변수가 없다면 단순 오름차순으로 정렬을 진행한다. 하지만 매개변수로 Comparator를 입력하면 해당 Comparator에 정의된 대로 요소를 정렬하게 된다.
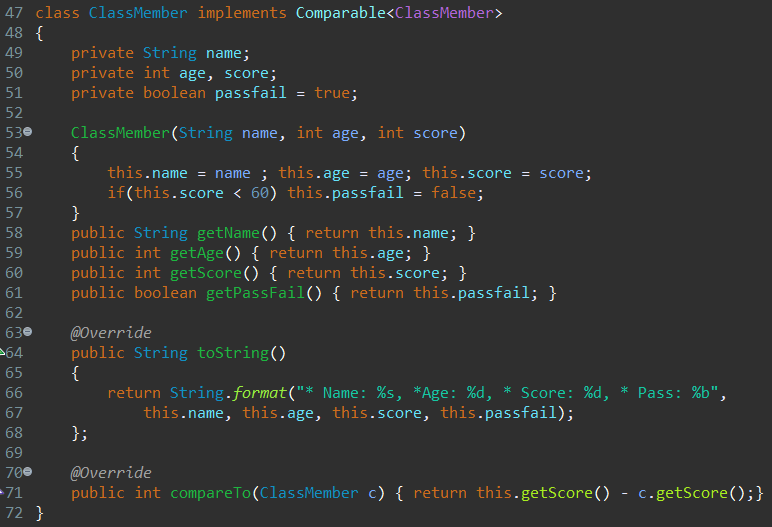
필자가 요즘 골프에 빠져 있으니, 이와 관련된 코드를 한 번 작성해보려 한다. 어떤 사람이 골프채 7번, 5번으로 연습중이고, 한 번 채를 휘두를 때마다 공의 비거리(공이 날아가는 총 거리), 캐리(공이 공중에 떠서 날아가는 거리)를 기록한다고 가정해보자. 그리고 이 정보를 하나의 클래스로 정의한 뒤, 모든 정보를 Stream 형태로 저장하려한다.
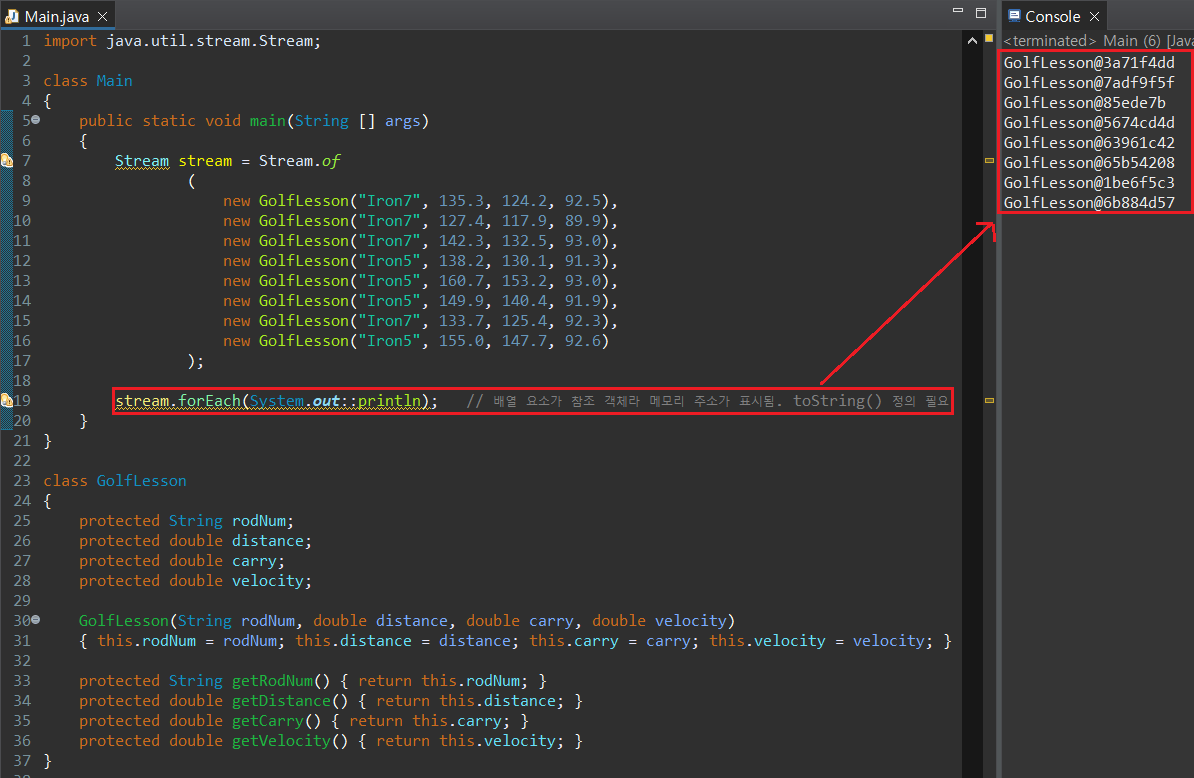
이들을 forEach()로 출력해보면, 각 요소들이 참조객체이므로 각 객체의 메모리 주소가 반환된다. 따라서 toString()을 사용하여 출력되는 문구를 아래와 같이 수정해준다.

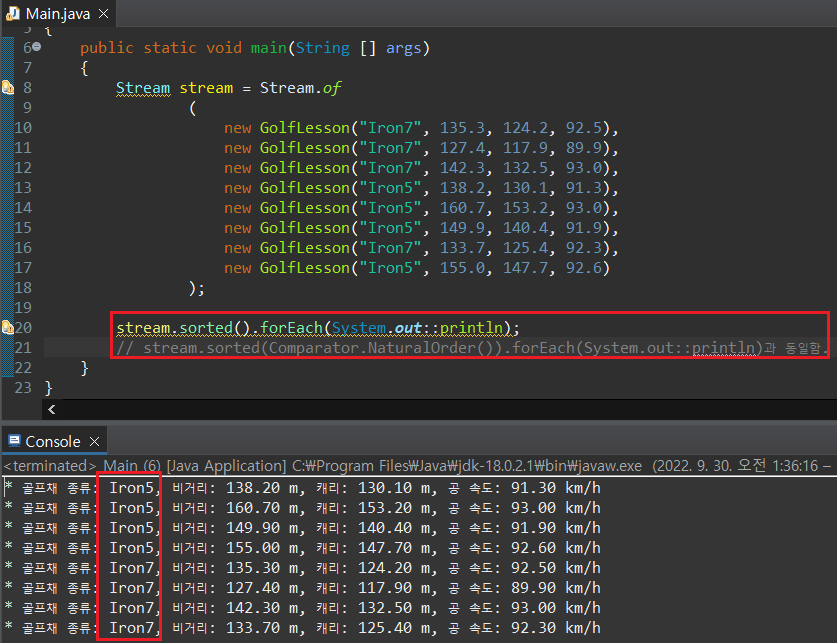
이제 개별 정보에 대한 비교를 진행해야 한다. Stream의 값을 비교하기 위해 sorted()를 사용하는데, 매개인자가 없다면 sorted는 기본으로 지정된 정렬 방식을 사용한다.
참조 객체간의 비교를 위해서는 Comparable이라는 인터페이스를 구현해야한다. Comparable은 추상 매서드로 compareTo()라는 매서드를 가지는데 Stream의 sorted() 매서드는 Comparable.compareTo() 매서드의 내용을 기본 정렬 방식으로 참고한다.
만약 골프채 번호로 정렬한 이후 비거리를 오름차순으로 정렬하고자 한다면 어떻게 해야할까? sorted() 매서드는 매개인자로 Comparator 객체를 받는다고 언급했다. 만약 람다식을 사용하여 Comparator를 생성하고자 한다면 Comparator.comparing() 매서드를 사용하면 된다.


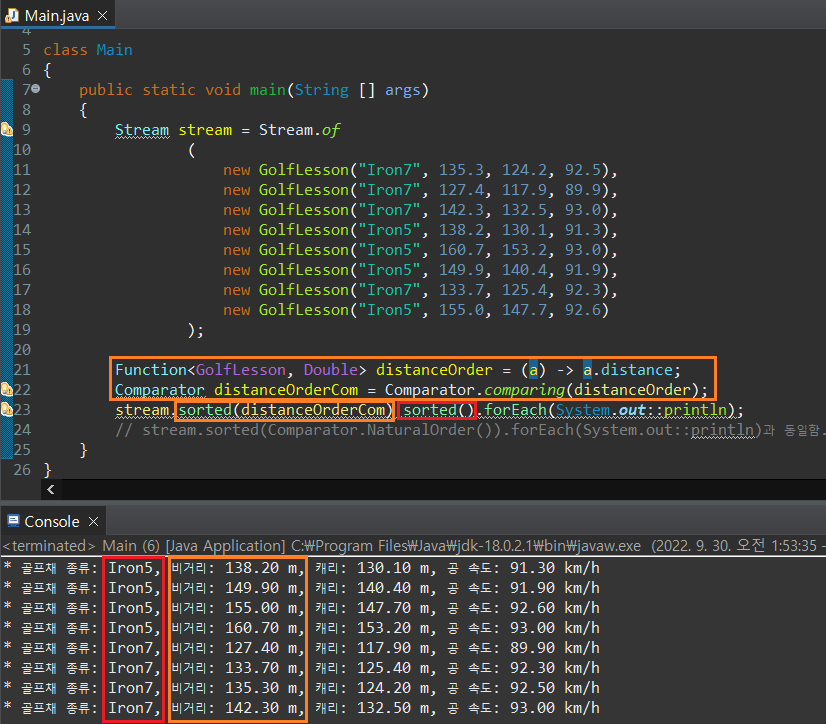
sorted() 매서드를 연속으로 두 번 사용하면서 특정 필드값들의 정렬을 유도할 수도 있지만, 이 때 코드 상에서 어떤 필드값이 먼저 정렬되었는지 알기가 어렵다. 위의 예시에서도 필자는 골프채 번호를 먼저 기본 정렬로 진행했지만, 코드 상에서는 sorted(distance)가 먼저 등장하여 마치 비거리를 우선으로 정렬된 듯한 인상을 준다.
람다식 합성의 andThen() 매서드와 유사하게, Comparator역시 thenComparing()이라는 매서드를 통해 sorted 조건을 합성할 수 있다. 이 매서드를 사용하면 데이터 정렬 기준이 무엇이 우선되었는지 코드상으로 조금 더 알기 쉬워진다.
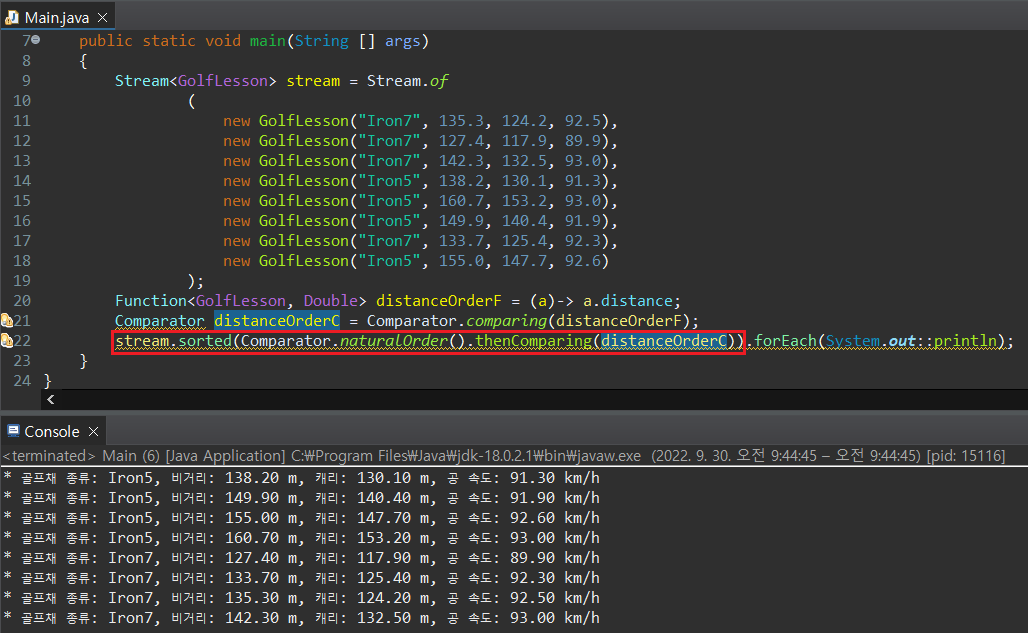
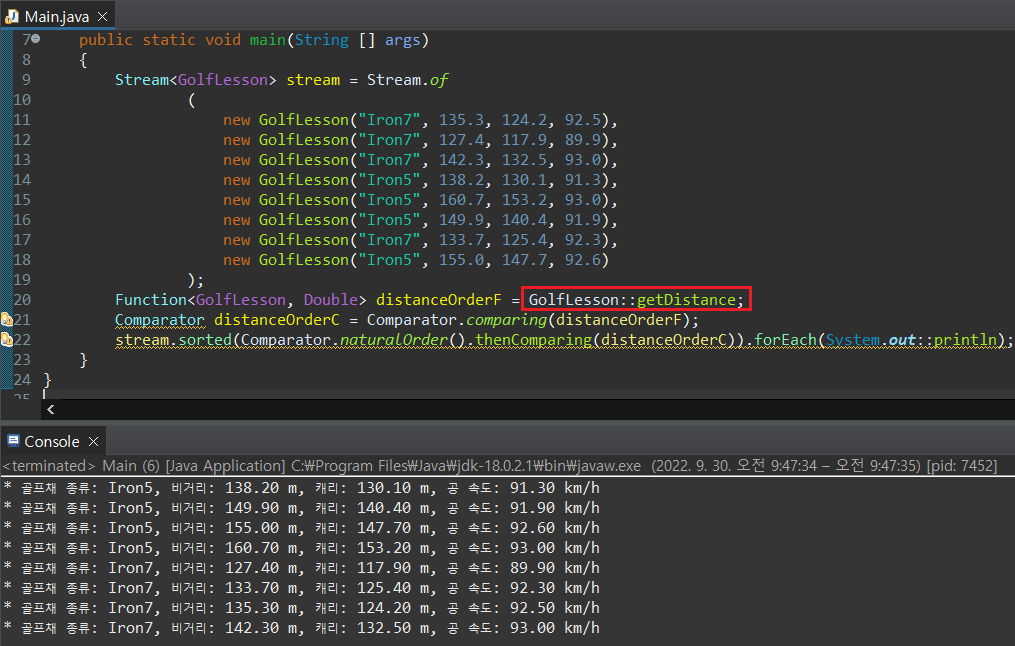
Comparator.comparing() 매서드는 Comparable을 구현한 클래스 객체의 특정 값을 비교하여 Comparator 객체로 돌려주는 역할을 한다. 즉, comparing에 들어가는 매개인자 값은 거창한 것이 필요한 것이 아니라 단순히 특정 인스턴스 변수를 돌려받을 수 있는 매서드를 입력해주기만 해도 된다.
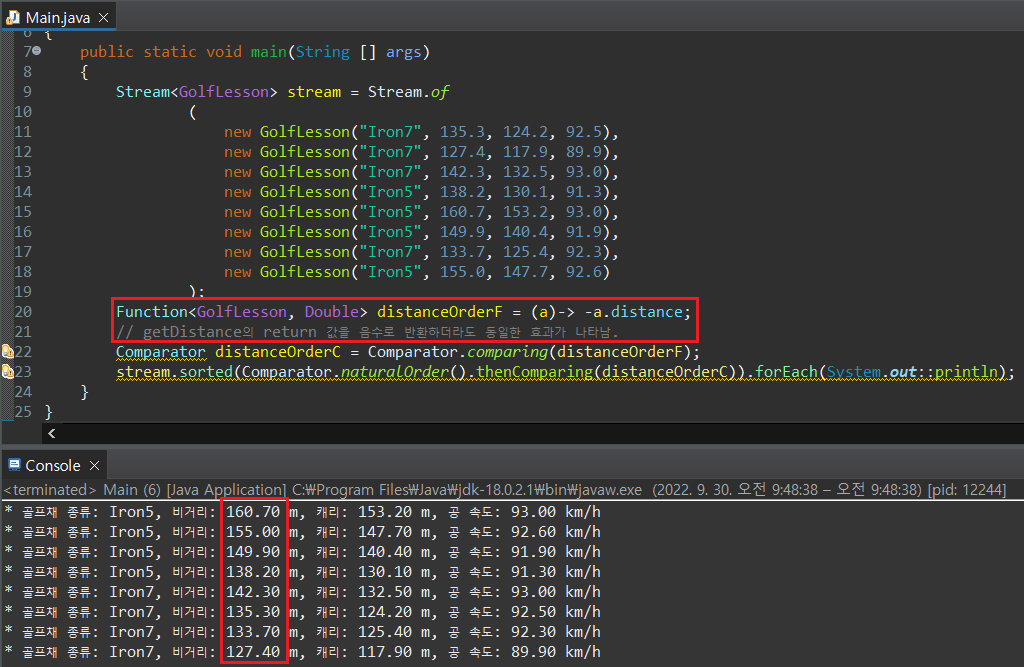
만약 오름차순이 아닌 내림차순으로 정렬하고 싶다면, 비교할 인스턴스 값에 -1을 적용하여 반환값으로 받으면 된다.
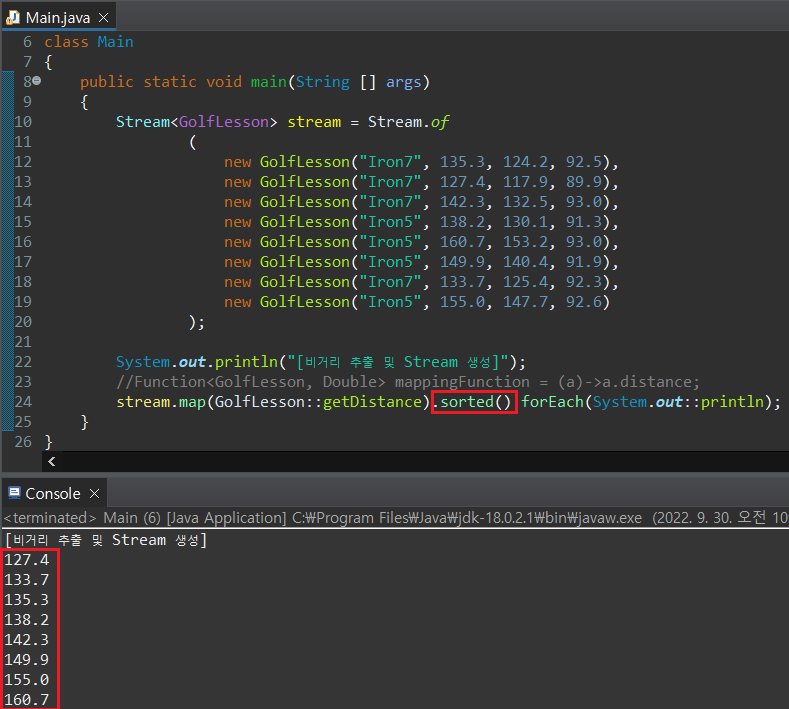
(2) map()
Stream으로 저장된 정보 중에서도 특정 필드만을 추출하여 Stream으로 저장하고 싶은 경우가 있다. 필자의 경우 현재의 예시에서 다른 정보들은 다 제쳐두고, 단지 비거리가 얼마나 나왔는지만을 화면상으로 출력하고 싶다. 이러려면 GolfLesson 객체 내에서 distance 값만 추출하여 Stream으로 전환해야 한다.
forEach() 문을 통해 화면으로 출력이 가능한 것은 알겠는데, 그럼 GolfLesson Stream에서 Double Stream으로 변경하는 매서드가 하나 있어야하고, 변경 매서드 내에는 특정 인스턴스 변수값(필드값)만 추출할 수 있도록 람다식 같은 것이 포함되어야 한다. Stream에서는 이 기능을 map()이라는 이름의 매서드로 제공한다.
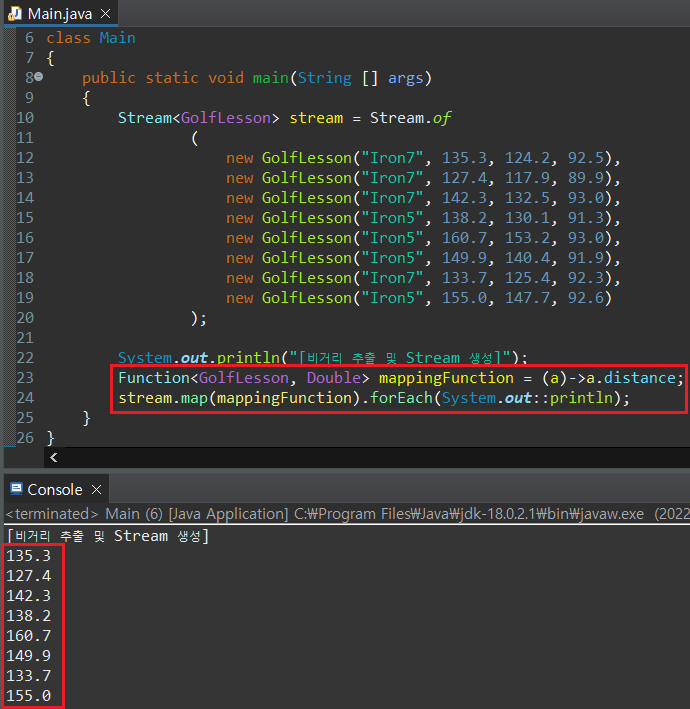
map() 매서드는 매개인자로 Function을 받는데, map()을 호출한 stream 객체가 Function의 입력값으로 작용하기 때문에 굳이 일반 람다식을 사용할 필요가 없다. 따라서 아래와 같이 메서드 참조형 람다식을 map()의 매개변수로 지정하는 것도 가능하다. 이 경우, stream 객체의 최종 형태는 Stream<Double>이 된다.

Stream이 Double 객체, 즉 Comparable을 구현받고 있는 클래스를 담고 있기 때문에 sorted()를 사용하면 Double.compareTo() 매서드에 지정된 기본 정렬 방식인 오름차순 방식으로 정렬이 진행되는 것을 확인할 수 있다.
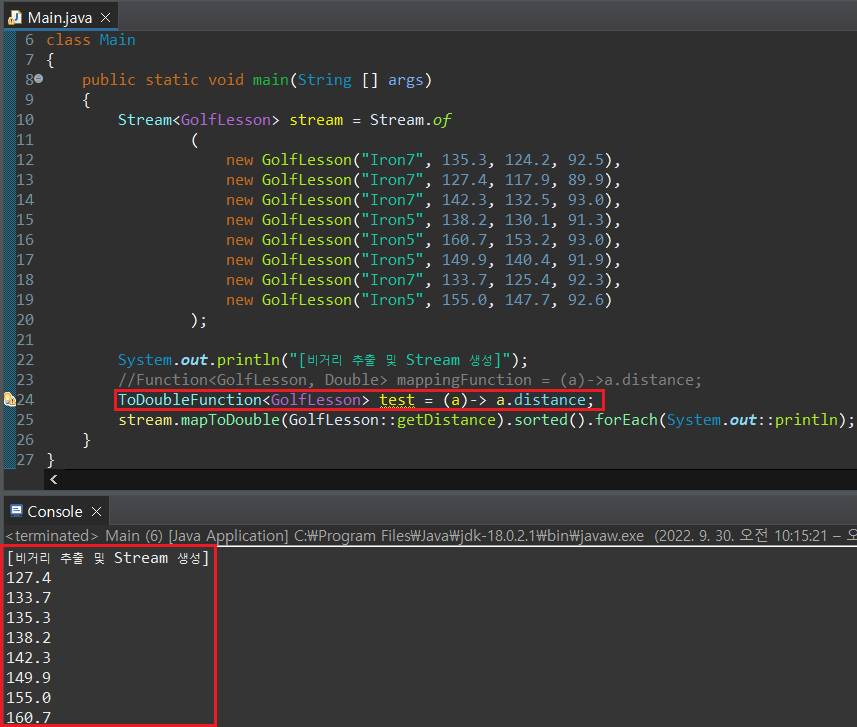
map() 매서드 역시 stream 객체를 특정 숫자 타입 객체로 변환할 수 있도록 파생된 매서드가 존재한다. mapToInt(), mapToDouble(), mapToLong()을 사용하면 되는데, 매개변수는 각각 Function 파생형인 ToIntFunction, ToDoubleFUnction, ToLongFunction을 사용한다.
(3) flatMap()
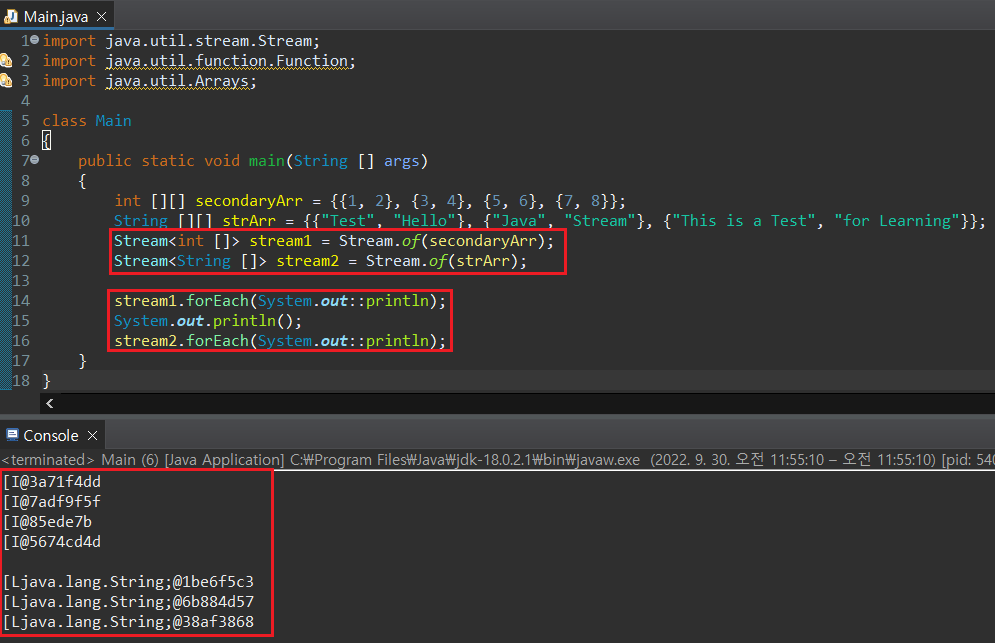
2차원 배열 역시 Stream으로 생성이 가능하다. 그런데, 2차원 배열을 Stream으로 생성하고 forEach()로 요소값을 출력해보면 각 요소들이 배열 타입이기 때문에 배열이 Stream 형태로 반환됨을 확인할 수 있다. int 및 String에 대한 2차원 배열을 만들어 Stream 생성을 진행해보자.
Stream 요소가 배열이기 때문에 요소에 대해 Stream을 적용하면 요소의 요소값이 나올 것이라 생각하기 쉬운데, 의외로 결과는 Stream 객체 정보가 반환되는 것을 확인할 수 있다.
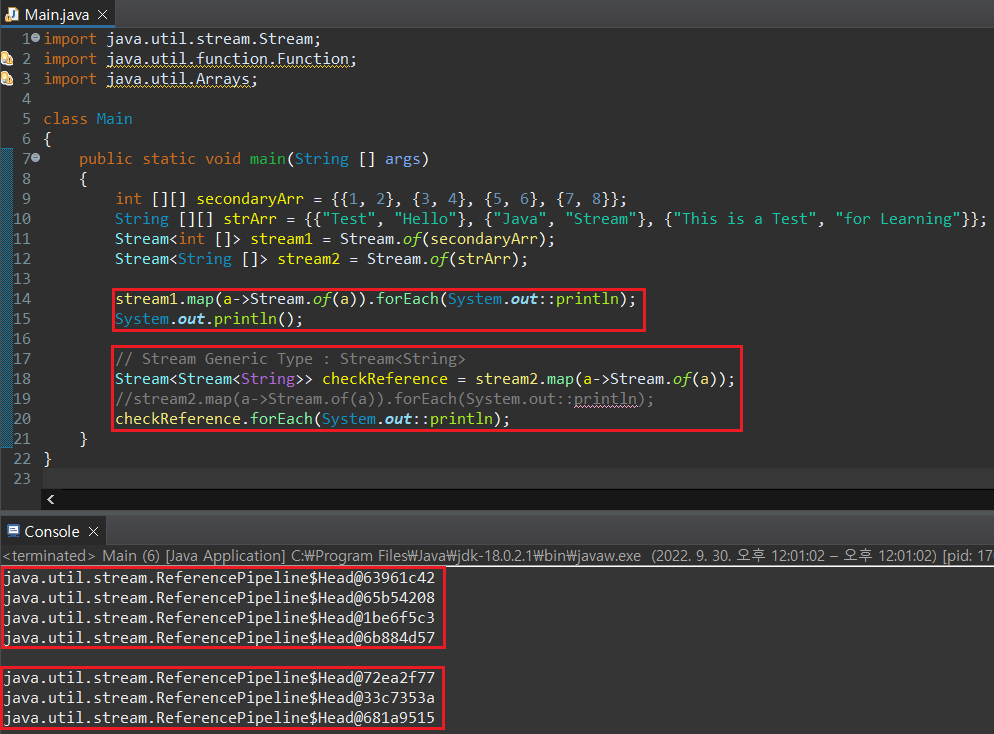
그럼, 요소의 요소값을 출력하기 위해 한 번 더 map()을 적용하면 되지 않을까? 요소값이 Stream 객체이기 때문에 Stream.of() 매개변수로 적용하면 왠지 나올 것 같다는 느낌이 들지만, Stream 객체는 배열이 아니기 때문에 map() 매서드에 의해 아무런 영향을 받지 못한다.

이차원 배열에서 요소인 배열이 Stream 객체로 저장된 경우, 해당 Stream의 요소 - 요소의 요소 - 값을 출력할 수 있는 방법을 Stream 클래스의 flatMap()이라는 매서드가 제공한다. 단, flatMap() 매서드는 첫 요소의 toString() 값에 따라 결과가 다르게 나타나는데, 정수형 배열은 toString()이 메모리 주소 형태로 반환되므로 요소의 요소값이 출력되지 않는 한편, String은 toString()의 결과가 요소의 형태를 띄기 때문에 정상적으로 요소의 요소값이 화면에 출력된다.
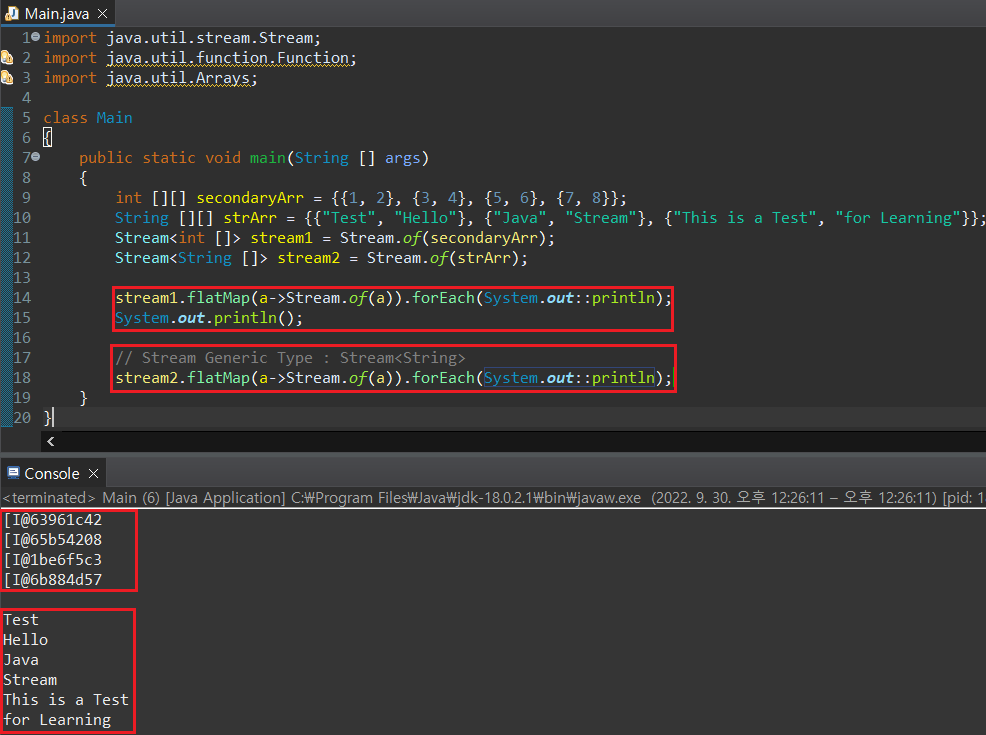
4. Optional 객체 타입 및 Optional 객체를 반환받는 최종 연산
최종 연산을 보면 Optional<T> 객체를 반환받는 매서드들이 몇 가지 보인다. 대표적으로 findAny(), findFirst(), reduce() 매서드 등이 있다. 이 Optional은 모든 객체를 담을 수 있는 객체인데, 마치 Stream이 배열과 관련된 객체를 모두 담을 수 있는 것과 동일한 역할을 한다고 보면 된다. 대상만 객체로 바뀐 것일 뿐이다.
Optional 클래스는 java.util.Optional에 정의되어 있다.
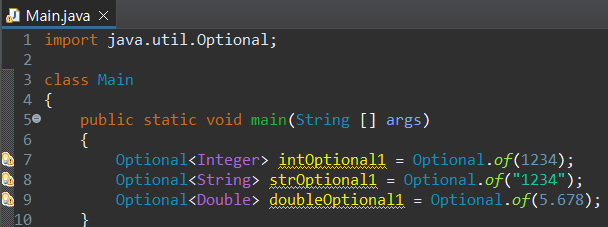
Optional 객체 역시 Stream 객체 생성과 동일하게 of() 매서드를 사용한다. 단, Stream이 Collections 객체에서 stream() 매서드를 제공하는 것과 달리 객체 자체에서 Optional을 생성할 수 있는 매서드는 별도로 제공하지 않는다. of() 외에도 ofNullable()이라는 매서드를 제공하는데, 이 매서드는 매개인자 값이 null인 경우 NullPointerException 예외를 발생시키는 of()의 기능에 예외처리만 추가한 것이라 보면 된다.
Optional 객체를 그대로 출력하면 Optional 객체에 대한 정보가 나타난다. 만약 저장된 값 자체만 출력하고 싶다면 get() 매서드를 사용하면 되고, 값이 저장되어 있는지 여부는 isEmpty(), isPresent() 매서드로 확인할 수 있다.
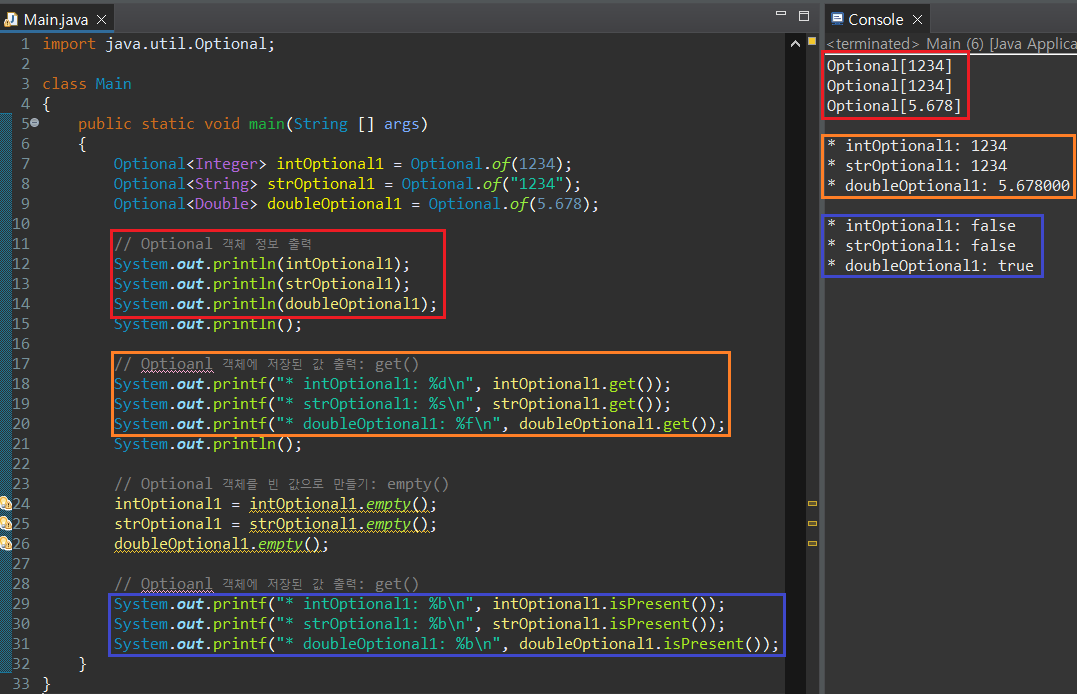
empty() 매서드로 Optional에 저장된 값을 null로 지정하는 것도 가능하다. 단, Stream과 달리 연산 후에도 객체 자체가 소멸되지 않고 결과값을 반환하기 때문에 empty() 매서드는 반드시 자기 자신의 Optional 객체를 반환받을 변수로 지정해야 저장된 값이 삭제된다. 또한, null 값이 Optional 객체에 저장되면 get() 매서드 호출 시 없는 값을 호출하는 것과 동일하기 때문에 NoSuchElementException 예외가 발생한다. Optional 클래스는 사실 이번 소단위의 주요 주제가 아니니 이 정도로 넘어가고...
Optional 객체를 반환하는 최종 연산 중 reduce() 하나만 예시로 살펴보자. reduce()는 매개인자로 람다식을 받는데, Stream의 각 요소를 람다식에 차례로 적용하면서 축적된 연산을 진행한다. 결과적으로 최종 연산값이 단 한 개만 반환되도록 하는 매서드다. 가장 많이 사용하는 예시로 정수형 Stream의 각 요소를 총합을 연산하는 것을 들 수 있다.
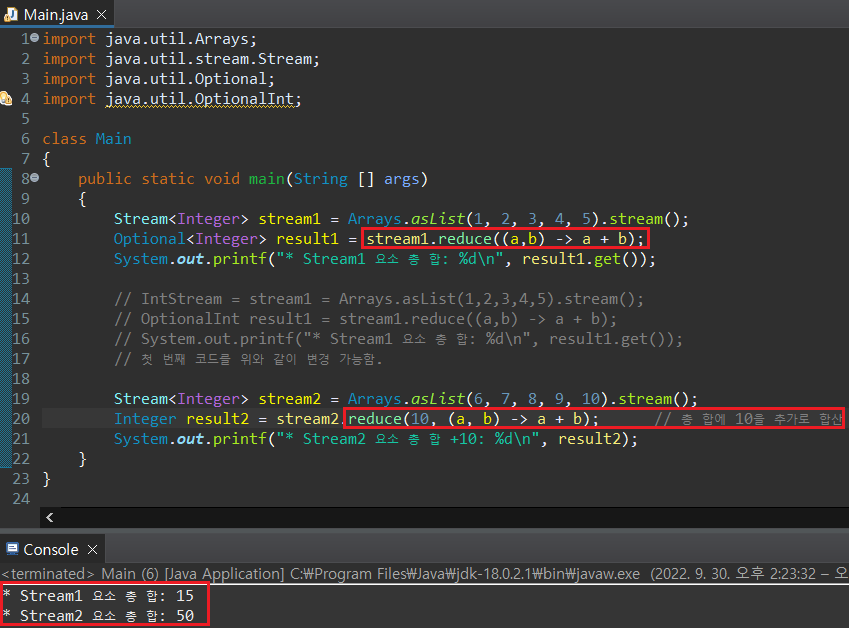
이렇게 각 요소를 축적으로 연산(Accumulative Operation)을 진행하는 동시에 Stream 요소를 줄여나가는 과정을 Reduction Operation이라고 한다.
findAny()와 findFirst() 역시 Optional 객체를 반환값으로 받으나, Optional 객체에 대해 조금이나마 이해를 한다면 이 매서드들은 사용방법도 크게 어렵지 않으므로 예시 없어 넘어간다. 사실 reduce() 매서드만 따로 설명을 진행한 이유는 다음으로 살펴볼 collect() 매서드와 관계가 있기 때문이다.
5. Collector, Collectors 클래스와 Stream.collect() 매서드
Stream 클래스에 정의된 collect()의 기능을 간략히 설명하면, Stream 객체의 요소들을 컬렉션 프레임워크(Collection Framework) 타입으로의 저장이다. 즉, Stream을 List, Set, Map 형태로 변환하며, 새로 생성할 컬렉션 프레임워크에 어떤 자료만을 담을지 결정한다고 보면 된다(배열로 변환하는 기능는 Stream.toArray()에 정의되어 있다).
Collect()는 매개변수로 Collector 객체를 받는다. 이와 관련된 인터페이스와 클래스는 java.util.stream 패키지에 속한 Collector 인터페이스와 Collectors 클래스가 있다.

Collector는 인터페이스를 구현한 클래스 내에 인터페이스의 추상 매서드를 정의하여, Stream을 추출하는 방식을 정의하는데 사용한다. Collectors는 자주 사용하는 기능에 대해 매서드로 정의한 클래스로 마치 배열의 Arrays 클래스와 같은 역할을 한다고 보면 된다. 이러한 이유로 Collectors 클래스의 매서드는 전부 반환 타입이 Collector다.
Collectors 인터페이스는 supplier(), accumulator(), combiner(), finisher(), characterirstics()라는 추상 메서드가 설계되어 있는데, Collectors 인터페이스를 구현한 클래스 내부에 이들 매서드를 정의함으로써, Stream을 특정한 객체 타입으로 변환할 수 있게 된다. 이건 조금 뒤에 살펴보고...
먼저 Collectors 클래스의 매서드부터 살펴보자.
(1) Collectors 클래스의 매서드
Collectors 클래스는 Stream을 배열 및 컬렉션 프레임워크로 변경하는 기본적인 매서드 뿐만 아니라, 통계, 결합, 축적 및 Reduction 연산, 그룹화로 특정 자료만 추출하는 등의 여러 매서드를 제공한다.
[ Stream 객체의 배열 및 컬렉션 프레임워크로 변경 ]
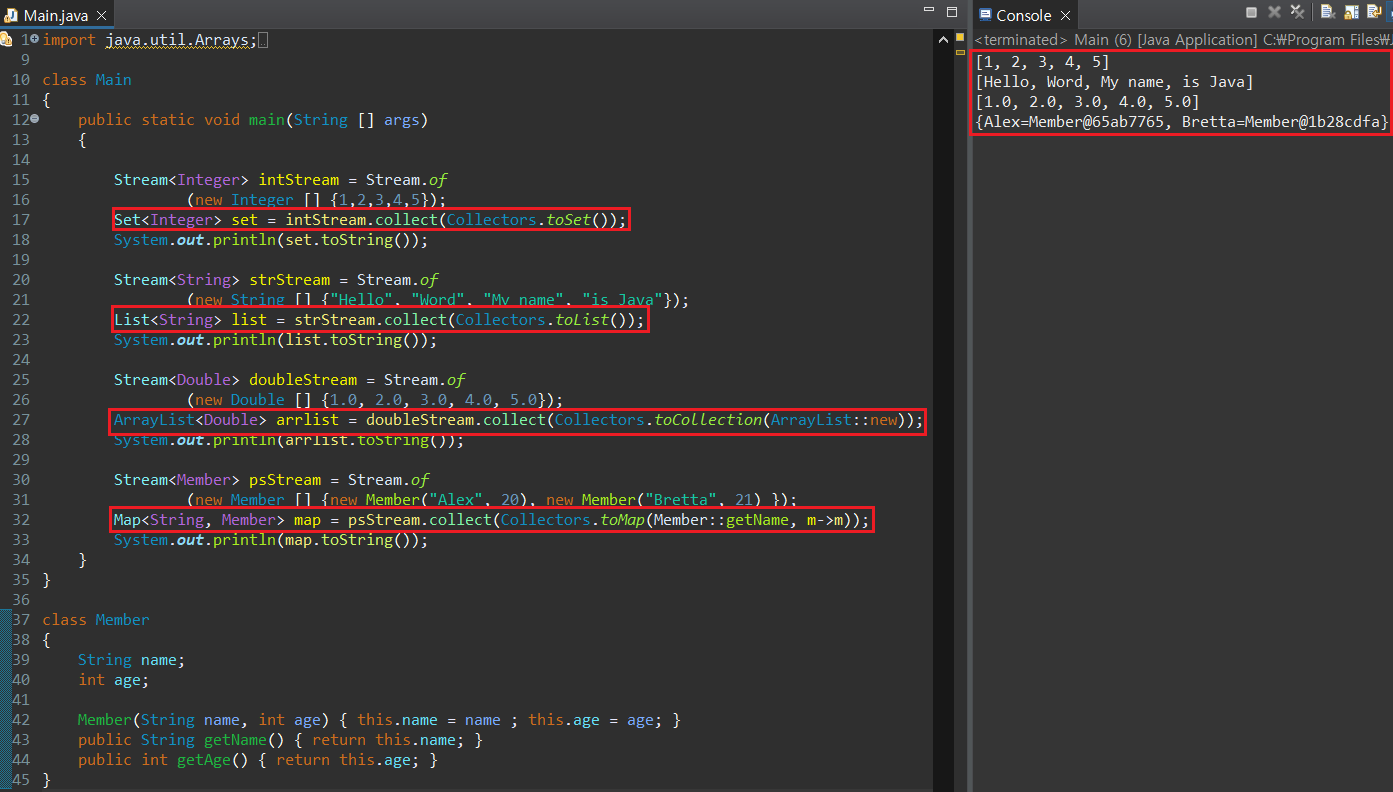
* Collectors.toList() : Stream 객체를 List로 변경. 반환값 객체는 List.
* Collectors.toSet() : Stream 객체를 Set으로 변경. 반환값 객체는 Set.
* Collectors.toMap(Function Key추출, Function Value추출): Stream 객체를 Map으로 변경. 반환값은 Map.
Map 특성 상 toMap()은 매개변수로 두 개의 Function 람다식을 사용함.
* Collectors.toCollection(Supplier s): Stream 객체를 특정 객체로 변경.
매개변수 s는 보통 변환할 객체의 생성자를 람다식으로 생성함.
[ 통계 관련 매서드]
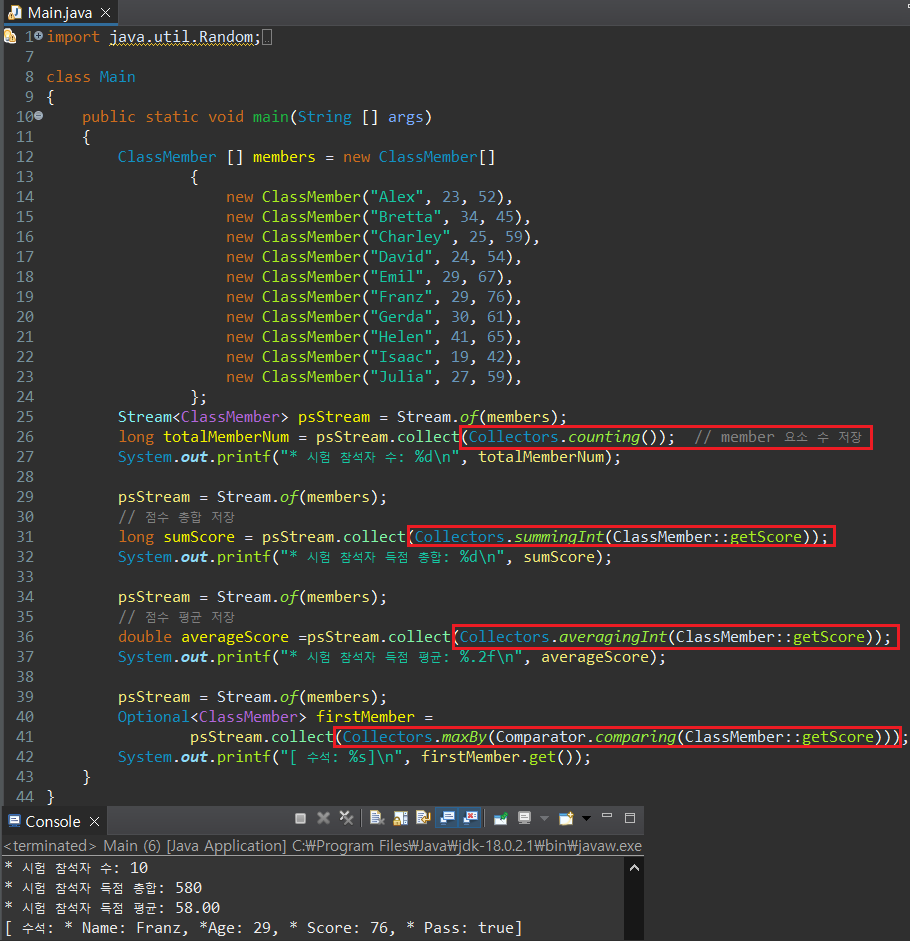
* Collectors.counting() : Stream 요소의 수량을 반환함.
* Collectors.summingInt() : Stream 요소의 특정 정수값의 합을 반환함.
매개변수로 총합을 계산할 대상을 람다식으로 지정함
* Collectors.averagingInt() : Stream 요소의 특정 정수값의 평균을 반환함.
매개변수로 평균을 계산할 대상을 람다식으로 지정함
* Collectors.maxBy() : Stream 요소의 특정 값이 가장 높은 대상을 반환함.
매개변수로 비교를 진행할 대상에 대한 Comparator를 람다식으로 지정함.
위에서 예시로 들은 통계 관련 매서드는 모두 Stream의 각 요소를 연산하며 최종 결과값으로 수렴하는 reduction operation이다. 따라서 동일하게 reduction Operation을 수행하는 reduce() 매서드로, 이들 통계 매서드를 구현할 수 있다.
[ 그룹화와 분류 / 분할 관련 매서드 ]
사실 위에서 설명한 매서드는 굳이 collect() 매서드와 Collectors 클래스를 거치지 않더라도 다른 방법으로 결과를 도출할 수 있다. 통계 관련 내용은 앞서 보았던 IntSummaryStatistics 클래스를 활용하면 되고, Stream의 변환 역시 Stream 클래스에서 동일한 이름을 가지는 매서드들이 그 역할을 담당하기 때문에 사실상 Collectors 클래스를 호출해가면서까지 사용해야 할 필요성은 거의 느낄 수 없다. 하지만 참조 타입이 요소로 저장된 Stream에서 특정 조건에 따라 자료를 그룹화하거나 분할하는 작업에서는 collect() 매서드와 Collectors가 반드시 필요하다. 그룹화와 분류 / 분할과 관련된 매서드는 아래와 같다.
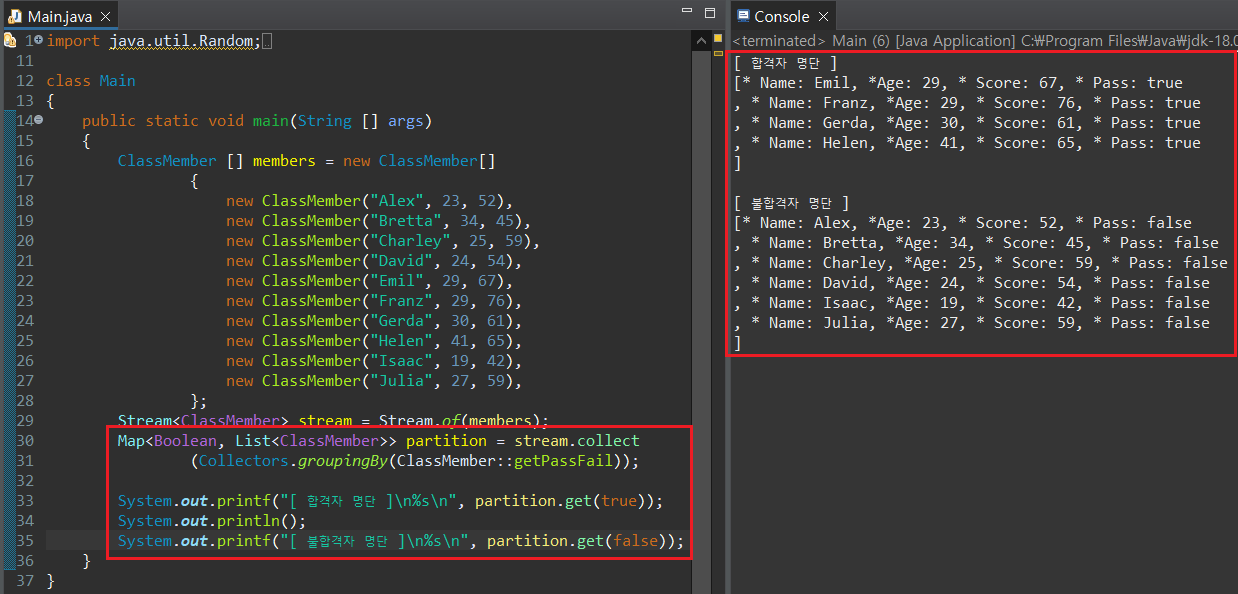
* Collectors.partitioningBy(Predicate p) : 조건 P를 만족하는지 아닌지에 따라 Stream을 분리하여 Map 타입으로 저장함. Key 값은 true / false로 지정되며, Predicate 조건 만족 여부에 따라 Stream 요소가 Value인 LIst에 저장됨.
* Collectors.groupingBy(Function f) : 조건 f를 만족하는지 아닌지에 따라 Stream을 분리하여 Map 타입으로 저장함. Key 값은 true / false로 지정되며, Predicate 조건 만족 여부에 따라 Stream 요소가 Value인 LIst에 저장됨.
두 매서드 모두 특정 조건의 만족 여부에 따라 Map의 Key를 true / false로 생성하여 값을 List로 저장한다는 것은 동일하다.

얼핏 보면 partitioningBy와 groupingBy가 큰 차이가 없는 듯 싶다. 조건에 따라 true/false로 나뉘어져서 Map에 저장되는 결과만 보면 말이다. 이번에는 partitioningBy()의 오버로딩 매서드를 활용하여 합격자 중 70점 이상 득점한 합격자만 별도로 추출한다고 가정해보자.
* partitioningBy(Predicate p, Collectors c) : Predicate 조건에 의해 나누어진 Stream 결과에서 Collector 연산 c를 진행하여 새 Map을 생성함.
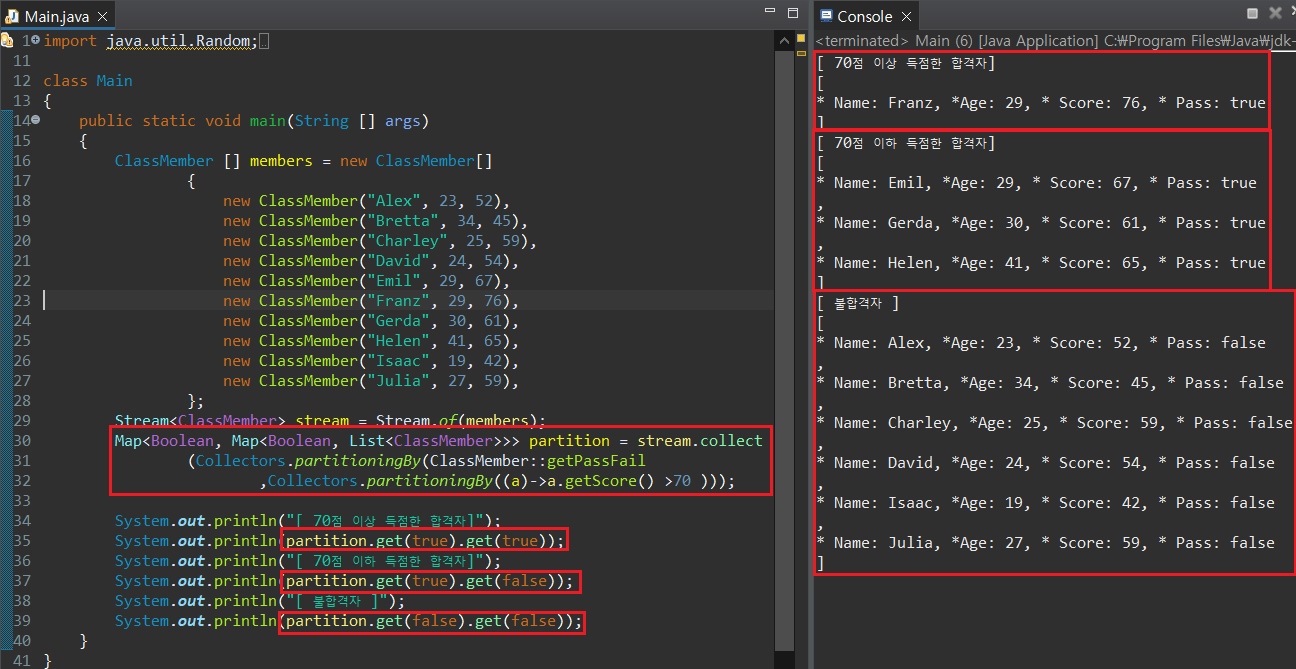
연산 결과를 출력하는 코드를 보면 알겠지만, Map()의 키가 단순히 true/false로만 저장되기 때문에 호출 시에서 get() 매서드 안에 true/false 만 인자로 사용하는 것이 보인다. 이럴 경우, 코드만을 보고 어떤 자료를 추출하기 위해 사용한 것인지 추후 알기 어려워진다. 이번에는 groupingBy()의 오버로딩 매서드를 사용해보자.먼저 시험 합격자와 불합격자를 Map Key "Pass" / "Fail"로 나누어보자.
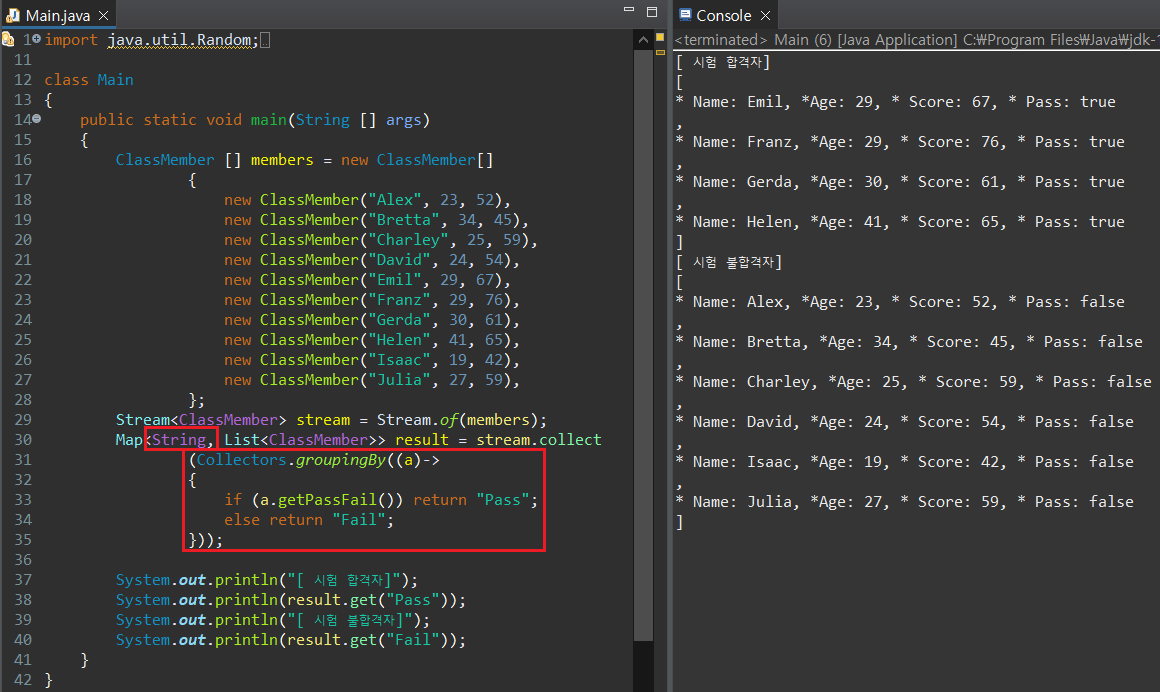
groupingBy는 Function을 매개변수로 받기 때문에 Stream 분할 시 Key 값을 원하는대로 지정하는 것이 가능하다. 필자의 경우 String으로 "Pass", "Fail"을 돌려주는 조건으로 groupingBy 람다식을 지정해주었기 때문에, partitioningBy 결과에서 Key를 true, false로 호출한 것과 달리 "Pass", "Fail"로 호출이 가능해진다. groupingBy() 매서드는 두 번째 인자로 Collectors 객체를 입력하면, 반환받은 결과를 기반으로 매개변수의 Collectors 연산을 다시 진행하게 된다. 이제 점수를 세분화하여 Map에 저장보자.
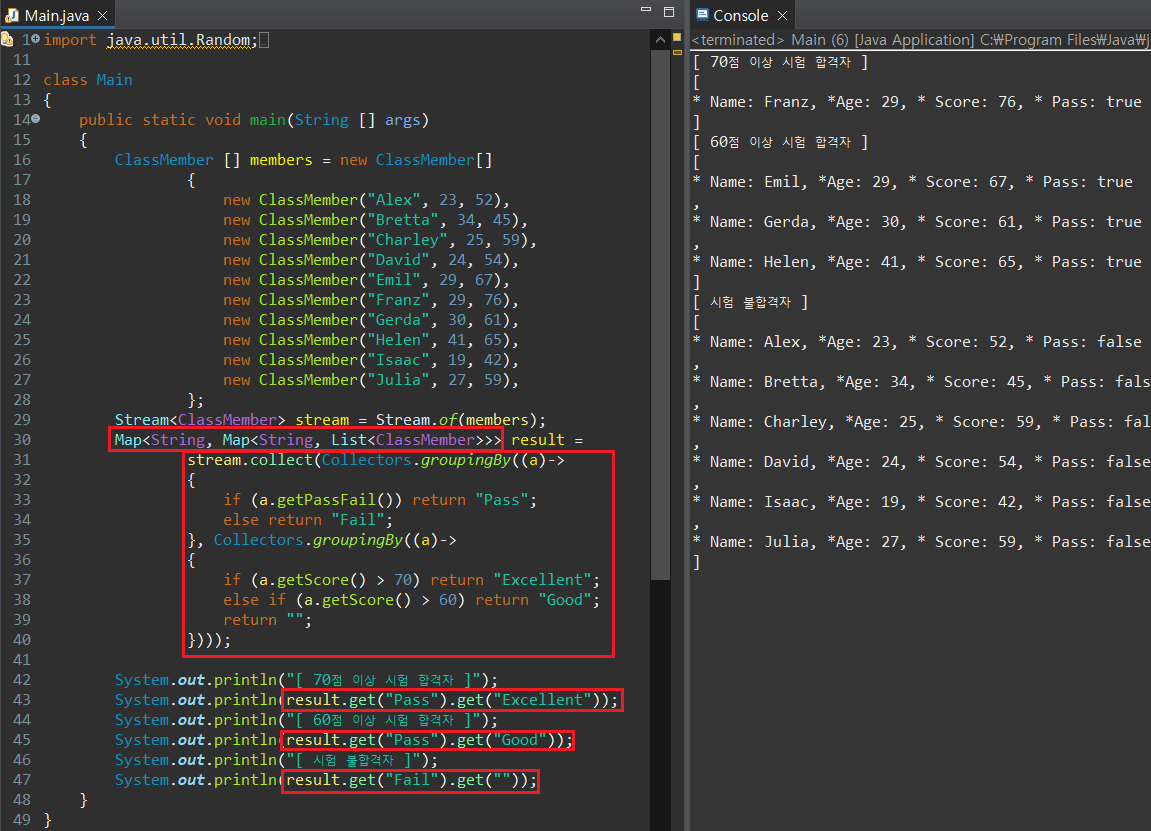
partitioningBy()에 비해 groupingBy()를 활용함으로써 Map으로 저장된 정보를 조금 더 효율적으로 다룰 수 있게 되었다. 아무래도 Boolean만 반환 가능한 partitioningBy()에 비해, Function 객체를 매개변수로 받아 반환값을 지정할 수 있는 groupingBy()는 Map에 저장되는 Key 값을 직접 지정할 수 있기 때문이다.
참고로, Eclipse에서 partitioningBy()와 groupingBy() 매서드에서 람다식을 블록 처리하여 작성하는 경우, 입력값에 대한 객체 매서드가 정확히 표시되지 않는 현상이 있는데, 절대 잘못된 것이 아니니 당황하지 않아도 된다. 필자는 ClassMember 객체 목록이 자동으로 표시되지 않아 코드를 잘못 작성했다는 판단에 한참이나 헤매었다(포스팅이 무려 5일만에 올라온 이유가 이거다...).
(2) Collector 인터페이스 직접 구현
지금까지는 Collectors 클래스에 정의된 매서드를 활용하여 Stream으로부터 추출할 내용을 정의하였다. 마지막으로, 이번에는 직접 Collector 인터페이스의 추상 매서드를 정의함으로써, stream으로부터 추출하고자 하는 값을 직접 지정하는 방법에 대해 알아보려한다.
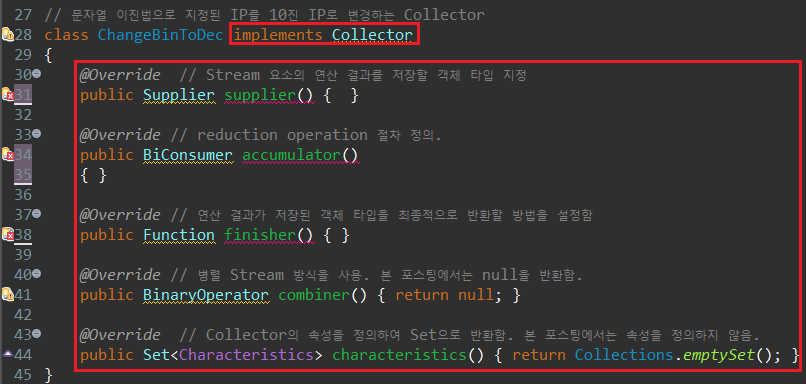
앞서 살짝 언급한대로 Collector 인터페이스는 다섯 가지 추상 메서드가 설계되어 있다.
* supplier() : 작업 결과를 저장할 타입 지정, 반환 타입은 Supplier
* accumulator() : Stream 요소의 수집 방법을 제공. 반환 타입은 BiConsumer
* combiner() : 병렬 스트림에서 두 저장공간을 병합할 방법을 제공.반환 타입은 Function
* finisher() : 결과를 최종 변환하는 방법 제공. 반환 타입은 Function
* characteristics() : Collector의 수행 작업 속성 정보 제공 용도. 반환 타입은 Set
Stream 작업을 진행할 클래스에 Collector 인터페이스를 구현하고, 클래스 내부에 인터페이스의 추상 매서드를 정의해주면 되며, 이렇게 생성한 Class는 Stream. 클래스의 collect() 매개변수로 사용이 가능해진다.
아주 간단한 예제를 하나 들어보자. 컴퓨터 통신에 사용되는 IP에 대한 내용이다.
인터넷을 통해 사이트에 접속하거나 혹은 카카오톡으로 메세지를 보내는 모든 행위는 컴퓨터에 부여된 IP 주소를 기반으로 한다. 간단히 IP 주소를 설명하자면, 0~255 사이의 숫자 4개가 점(.)을 구분자로 사용하여 나열된 형태이며, 각 숫자는 전문용어로 옥텟(Octet)이라고 한다.
하지만 컴퓨터는 십진수를 이해할 수 없기 때문에 이 숫자들을 이진법으로 변환하여 통신에 활용한다. 즉, 192.168.10.1은 "11000000.10101000.00001010.00000001"로 나타낼 수 있다. 각 숫자가 옥텟이라는 용어로 불리는 이유는 이진법 8자리(Octa) 수로 표시되기 때문이다.
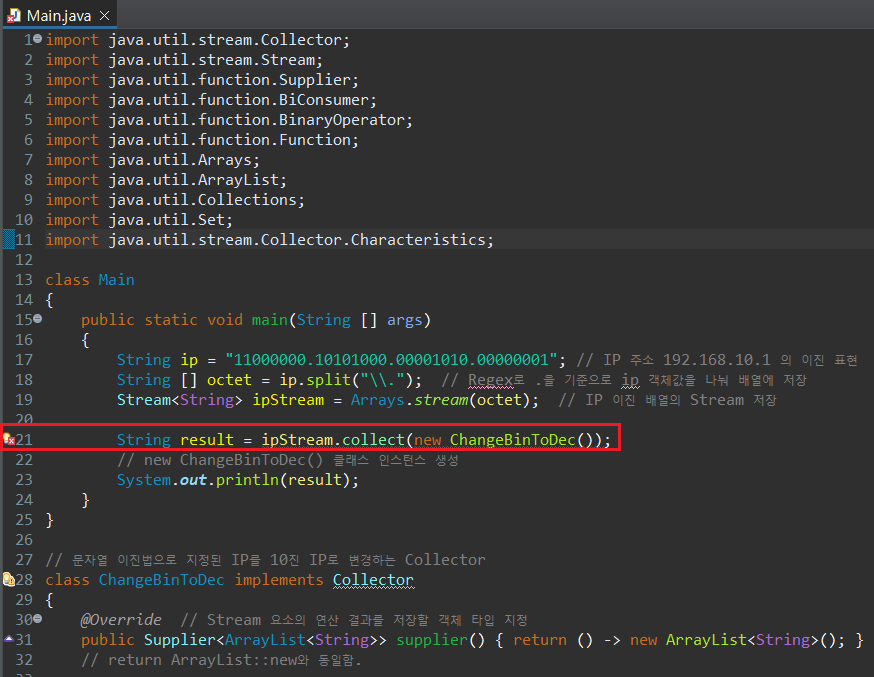
문자열로 받은 이진수 IP의 각 옥텟을, 문자열 십진수로 변경하여 반환하는 기능을, 위에서 알아보았던 Collector 인터페이스를 활용하여 만들어보자. 먼저 Main 함수부터 작성해보자.
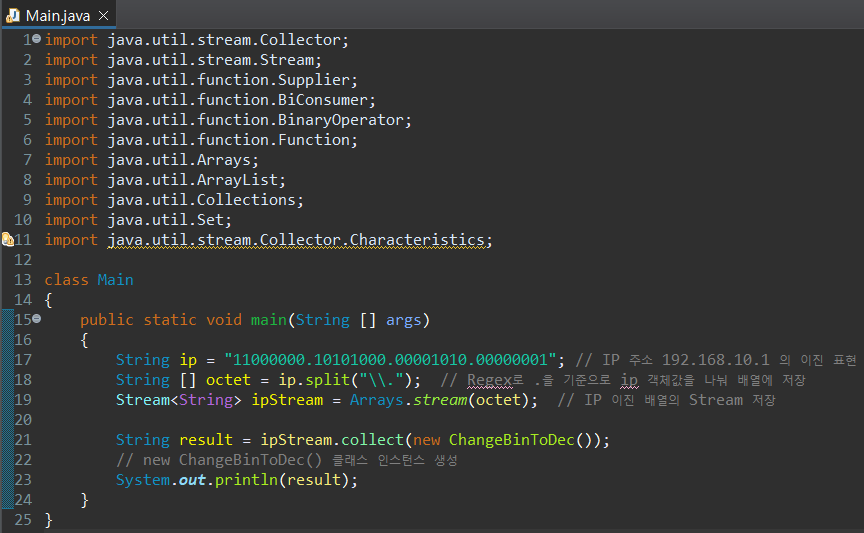
Main 함수 코드는 크게 어려운 것이 없다. 문자열 배열에 각 옥텟을 split("\\.")으로 구분하여 저장한 뒤 Stream으로 변경하고, 이 Stream으로부터 collect() 매서드를 사용하여, 필자가 원하는 10진 결과가 반환되도록 만들면 된다.
이제 가장 중요한 ChangeBinToDec 클래스를 만들어보자. 우선 Stream의 정보를 가공하기 위해 이 클래스는 Collector 인터페이스를 구현해야하며, 인터페이스 내 추상 매서드를 정의해야한다.
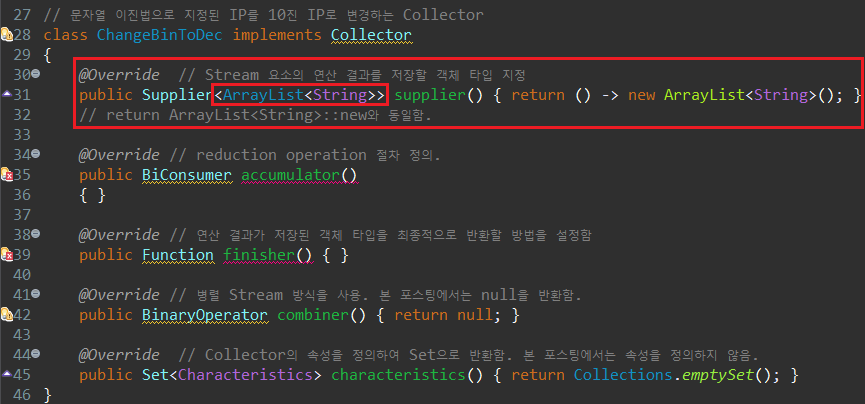
먼저 supplier() 매서드부터 보자. 필자의 경우, 문자열 이진 옥텟값의 연산이 완료되면, 연산 결과값을 ArrayList에 저장하려한다. 따라서 Supplier에는 ArrayList의 인스턴스, 즉 연산 결과를 저장할 객체의 인스턴스를 생성하는 코드를 작성하면 된다.
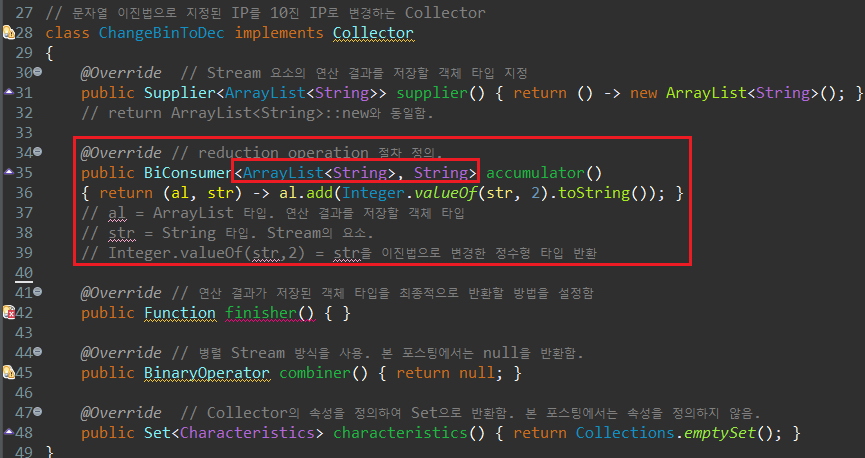
다음으로 각 요소에 대해 진행할 연산을 accumulator에 정의해보자. BiConsumer를 반환값 타입으로 지정하는 매서드기 때문에 반드시 입력값이 두 개, 출력값이 없는 람다식을 반환해주어야 한다. 이 매서드에서는 연산을 진행할 요소로 이진법 전환을 진행한 뒤, 연산 결과를 ArrayList에 저장하는 절차가 정의되어야 한다.
마지막으로 연산 결과가 저장된 ArrayList를 어떤 타입으로 반환할지 생각해보자. Main 함수에서, stream.collect()의 결과로 반환되는 값을 String으로 받는 것으로 정의하였기 때문에, finisher()의 반환값 역시 String이 되어야한다.
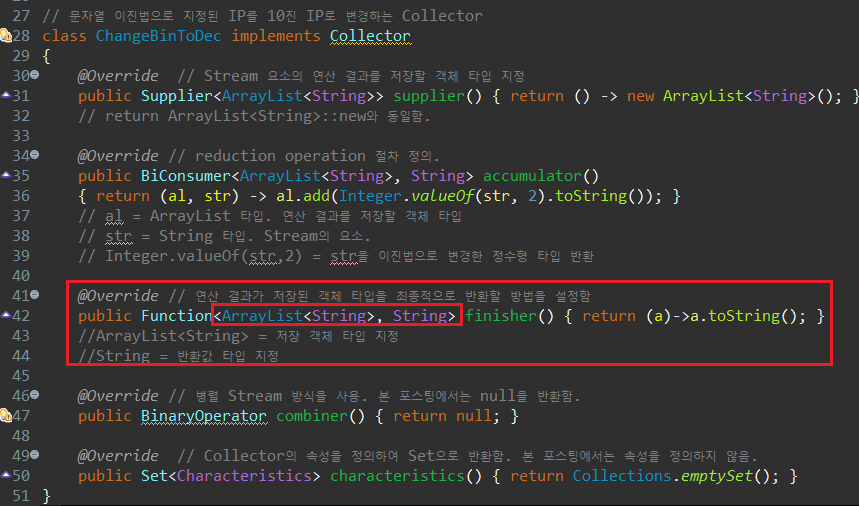
이제 인터페이스에서 구현해야하는 매서드는 모두 정의가 끝났다. 하지만 Main() 매서드의 collect() 코드는 여전히 에러를 표시할텐데, 이는 ChangeBinToDec에 구현한 인터페이스의 Generics가 정의되어 있지 않기 때문이다. 클래스 코드 내에는 모두 Generics가 적용되었는데, Collector는 Generics가 적용되지 않았으니 지정하라는 의미다.
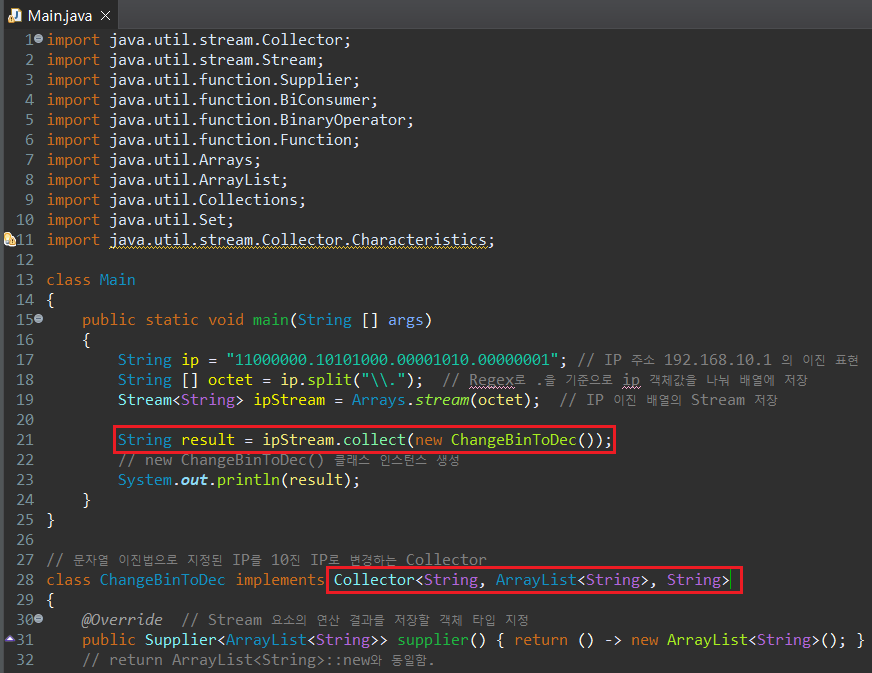
Collector의 Generics는 세 개의 타입을 지정해야한다.
Collector<Stream 요소의 타입, 연산 결과를 저장하는 객체의 타입(Collections), 저장할 객체 요소의 타입>.
위의 예시에서는 연산에 사용하는 stream 요소는 문자열이므로, 첫 Generics는 String을, 연산 결과는 ArrayList로 저장하므로 두 번 째 Generics는 ArrayList<String>으로, 연산 결과는 String으로 반환되므로 마지막 Generics는 Strings로 지정하면 된다.
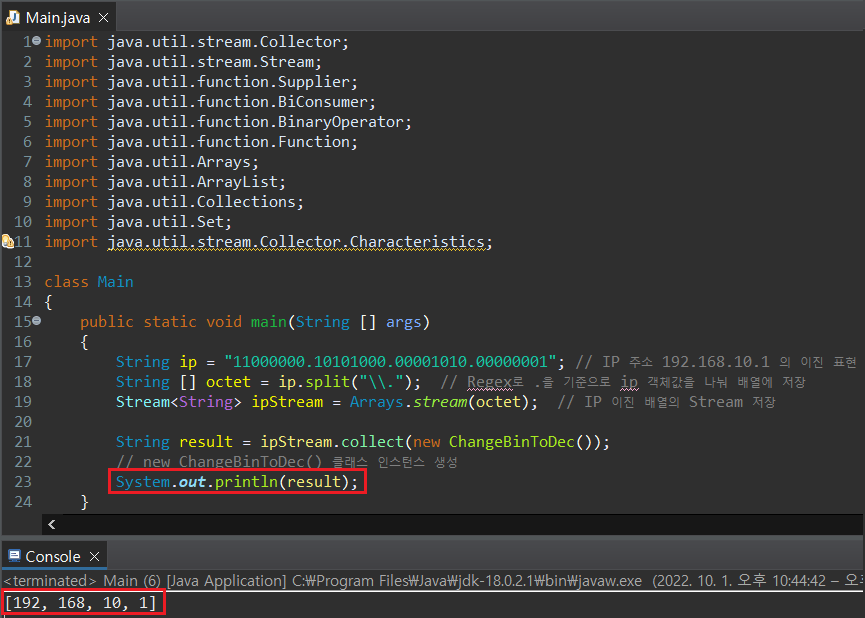
위의 코드를 실행하면, ArrayList에 저장된 십진수 옥텟 값이 List 형태로 출력된다.
실제 IP 주소와 동일한 포맷으로 나타내기 위해서는 finisher()의 람다식을 다음과 같이 수정하면 된다.
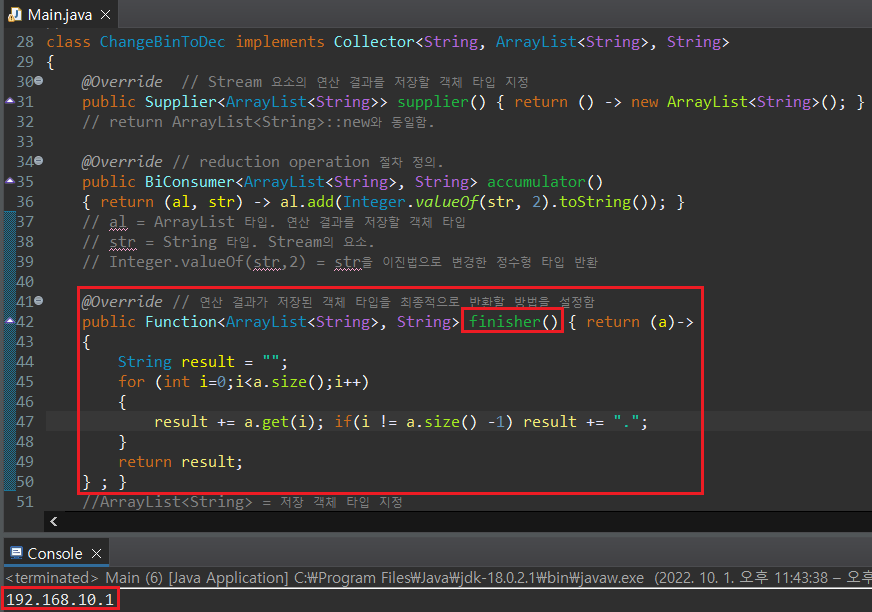
람다식과 Stream은 처음 접하면 이해하기가 영 까다로운 개념들이다. 그렇기 때문에 직접 코드를 입력하면서 어떻게 동작하는지 하나씩 확인해나가야 정확한 사용법을 숙지할 수 있다. 사실, "이렇게 복잡하게 코드를 작성해야 할 이유가 있을까"
라는 생각을 필자도 하지 않은 것은 아니지만, 여러 번의 삽질을 거듭하며 개념을 잡아가다보니(그래서 포스팅을 올리는게 5일이나 걸렸...), 좋은 가독성을 지니면서 유지보수가 용이한 코드를 작성하기 위해 반드시 알고 있어야 하는 내용이다.
다음 포스팅에서는 입출력 스트림(I/O Stream)에 대해 알아보려한다.
Fin.
'Java > Java Basic' 카테고리의 다른 글
| [Java Basic] 49 - Java I/O Stream2 - Serialization과 File 입출력 스트림 클래스 (0) | 2022.10.05 |
|---|---|
| [Java Basic] 48 - Java I/O Stream1 - Stream 클래스 및 보조Stream (0) | 2022.10.05 |
| [Java Basic] 46 - Java Lambda식과 함수형 인터페이스 (0) | 2022.09.27 |
| [Java Basic] 45 - Java Thread 4 - Lock 클래스, Condition 인터페이스 (0) | 2022.09.25 |
| [Java Basic] 44 - Java Thread 3 - Thread 동기화(Synchronized, wait(), notify()) (0) | 2022.09.23 |




댓글