지난 포스팅에서는 DataFrame의 index와 관련된 매서드에 대해 간략하게 알아보았다. 이번 포스팅에서는 데이터가 작성된 파일을 읽어들여 DataFrame으로 만들거나 DataFrame을 특정 파일로 저장하는 방법에 대해 조금 더 깊게 알아보려 한다. 앞서서 pandas 모듈에 대해 포스팅할 때 간략하게 언급했지만, 특정 데이터 정보만을 추출하는 부분과 데이터를 파일로 저장하는 내용이 누락되어 있어서 말이다...
오늘 포스팅에서 확인할 내용은 아래와 같다.
** 파일 읽기/쓰기의 경우, 데이터 분석에 많이 사용하는 csv, text, excel에 대해서만, 그 중에서도 csv에 대해 중점적으로 살펴볼 예정이다.
[ 데이터 파일 읽어오기 ]
# pandas.read_csv("파일명") : "파일명"의 데이터 읽어오기
- pandas.read_csv("파일명", skiprows = n) : "파일명"의 데이터 중 앞 n 줄을 제외하고 읽어오기(Column명 포함)
- pandas.read_csv("파일명", skipfooter = n, engine="python"): "파일명"의 데이터 중 뒷 n줄을 제외하고 읽어오기
- pandas.read_csv("파일명", nrows = n) : "파일명"의 데이터 중 앞 n줄만 읽어오기(Column 명 제외 n 줄)
- pandas.read_csv("파일명", index_col = "index로 지정할 Column명"): 특정 column을 index로 지정하여 데이터 읽기
- pandas.read_csv("파일명", usecols = "column명"): "파일명"의 데이터 중 특정 필드값만 읽어오기
# pandas.read_csv("텍스트파일명") : "텍스트파일명"의 데이터 읽어오기
- pandas.read_csv("텍스트파일명", sep = "구분자문자열") : "텍스트파일명"의 데이터를 "구분자문자열"로 구분하여
데이터 읽어오기
# pandas.read_excel("파일명") : "파일명"의 데이터 읽어오기
- pandas.read_excel("파일명", sheet_name = "시트이름"): "파일명" 데이터 중, 특정 시트의 데이터 호출
[ DataFrame 정보 파일로 저장하기 ]
# pandas.DataFrame.to_csv("파일명") : "파일명"으로 DataFrame을 csv저장
- pandas.DataFrame.to_csv("파일명", index=False) : DataFrame의 index 정보를 제외하고 csv 저장
# pandas.DataFrame.to_csv("텍스트파일명") : "파일명"으로 DataFrame을 텍스트 저장
- pandas.DataFrame.to_csv("텍스트파일명", sep = "구분자문자열"): DataFrame 필드들을 "구분자문자열"로 구분하여
텍스트 파일로 저장
# pandas.DataFrame.to_excel("파일명") : "파일명"으로 DataFrame을 excel 저장
- pandas.DataFrame.to_excel("파일명", sheet_name = "시트이름"): DataFrame 정보를 "시트이름"으로 excel 저장
** 공통사항
# pandas.DataFrame.to_{}("파일명", index = False) : "파일명"으로 DataFrame 저장 시, Index 값 제외
# pandas.DataFrame.to_{}("파일명", header = False) : "파일명"으로 DataFrame 저장 시, Column 명 제외
# pandas.DataFrame.to_{}("파일명", mode = "a") : "파일명"에 DataFrame 내용 추가.
이번 포스팅부터 이전에 필자가 직접 만들어 사용한 DataFrame이 아닌, 대량의 데이터가 포함된 파일을 기반으로 포스팅 내용을 작성한다. 실습이 필요하신 분들은 아래의 파일을 다운받아 사용하시면 된다.
첨부한 파일은 샘플 데이터로, 특정 기업의 근무자에 대한 인적정보, 연봉, 근속 연수 등이 포함된 자료이다. 본격적으로 자료의 데이터 파일의 내용을 불러오고 저장하는 방법에 대해 알아보자.
I. 데이터 파일을 DataFrame으로 불러오기
1. CSV 파일 불러오기 : pandas.read_csv("파일명")
코드를 보면 무엇을 의미하는지 명쾌히 알 수 있을 정도다. pandas 클래스의 read_csv() 매서드는 CSV 파일을 읽어들여 DataFrame 형식으로 변환하는 매시드다. 이전에 보았던 매서드들과 달리, DataFrame의 하위에 존재하는 매서드가 아닌 것만 주의하자.

보다시피, 파일 내의 행(rows)도 100줄이나 되며, column도 37개나 되기 때문에 cmd와 같은 인터프리터 환경에서 모든 데이터를 출력하는 것은 불가능하다. 따라서 행과 column의 중간에 줄임표 표시로 내용이 생략된 것이 보인다.
read_csv로 파일 내 데이터를 모두 DataFrame 형태로 변환하는 방법을 일반적으로는 많이 사용하지만, 실제 데이터를 다루다보면, 위의 예시와 달리 행이 120,000줄은 아무렇지도 않게 넘어가는 파일들을 종종 접하게 된다. 그러나 데이터분석에 이들 정보가 모두 필요한 것이 아니라면, 굳이 전체 데이터 내용을 DataFrame으로 변환하지 않고, 일부 행과 column만을 DataFrame으로 변환하는 것도 가능하다. 아무래도 많은 데이터를 DataFrame으로 전환하면 df를 출력하는 코드를 실행하는 것만으로도 지연이 있을 수 있기 때문이다.
# 첫 N줄은 제외하고 저장하기: skiprows(N)
pandas.read_csv() 매서드는 이 때문에 skiprows라는 인자를 사용할 수 있게 설계되어 있다. 이 skiprows는 특정 줄을 제외하고 csv 파일의 내용을 읽어들인다는 의미다. 필자는 앞의 97줄을 제외한 모든 데이터를 DataFrame으로 변환해보았다.

이 skiprows 사용 시, 주의해야 할 점이 있는데, column의 이름, 즉 필드명도 skiprows 사용 시 삭제 대상에 포함된다는 점이다. 다시 예시를 조금 수정해서 skiprows=1로 read_csv를 실행할 경우, Column명을 제외하고 나머지 데이터가 DataFrame으로 변환되며, csv 파일의 가장 첫 번째 row의 정보가 Column명으로 대체된다. 위의 경우도, 97번째 데이터인 ID 704709의 정보가 Column명으로 대체된 것을 확인할 수 있다. 따라서, Index 번호를 보면 알겠지만 실제 데이터도 3개가 DataFrame으로 변환된 것으로 인식된다.
그럼, 저 Column의 이름은 그대로 유지한 채 첫 N줄의 데이터를 삭제할 수 있는 방법은 없을까? 당연히 있다. skiprows의 값을 정수 리스트 형태로 입력하면, 리스트 내 번호에 해당하는 줄만 제외하고 출력하게 된다. 따라서, 필자가 1, 3, 5번째 정보만 삭제하고 DataFrame으로 정보를 변환하고자 한다면 아래와 같이 코드를 작성하면 된다.

이 방식을 사용하면 Column명은 유지한 채, 특정 행만 제외하고 DataFrame으로 변환하는 것이 가능하다. 조금 더 응용해서, 첫 97줄을 제외한 나머지를 DataFrame으로 변환하고자 한다면 아래와 같이 코드를 사용하면 된다.

# 마지막 N줄은 제외하고 저장하기: skipfooter(N, engine='python')
반대로, 마지막 N줄을 제외한 데이터를 변환하는 매서드는 skipfooter()다. skiprows와 달리 s가 매서드명에서 빠진다는 것만 유의하면 된다.

특이하게도 이 매서드를 사용하면 engine과 관련된 경고문이 나타나는데, 이 코드를 실행하는 기본 엔진인 'c'가 skipfooter를 지원하지 않기 때문에 나타나는 현상이다. 이 경고를 없애고 싶다면 engine="python"인자를 매서드 내에 추가해주면 된다.

skipfooter는 skiprows와 달리 list 형태의 값을 인식하지 못한다. 따라서 skipfooter를 사용하여 특정 행만을 지우는 행위는 진행할 수 없다.
# 첫 N줄 정보만 저장하기: nrows(N)
그럼, 파일 데이터 중 첫 N 줄만 저장하고자 한다면 어떻게 해야할까? skiprows로 [x for x in range(N,)]을 사용할 수도 있겠지만 너무 번거롭다. 다행히도 read_csv() 매서드는 nrows라는 인자를 지원하며, nrows의 값으로 행 수를 int 형태로 입력하면 파일의 첫 N줄만 추출하여 DataFrame형태로 변환해준다.

특이하게도, skiprows와 달리 nrows는 column명 부분을 N 값에 포함시키지 않는다. 따라서 skiprows와 달리 Column명이 명시된 행을 유지하기 위해 약간은 귀찮은 수식들(?)을 작성할 필요가 없다는 장점이 있다.
# 특정 Column을 Index로 지정하여 DataFrame 변환하기: index_col="column명"
read_csv로 파일 데이터를 DataFrame화 할 때, 특정 column값을 index로 지정할 수 있다. index_col이라는 인자가 그 역할을 하는데, 이 값이 지정되지 않은 경우 일반 DataFrame 생성 시 나타나는 기본 숫자(0부터 부여되는)가 index로 지정된다.
필자가 올린 CSV 파일 데이터 중, 데이터를 구분할 수 있는 키 필드명이 Emp ID이므로, 이 값을 Index로 지정하여 DataFrame으로 변환해보았다.

이전의 데이터들과 달리, Column의 숫자가 37에서 하나 줄어든 36개로 표시되는 것이 보인다. 이렇게 Index로 지정된 DataFrame의 index 수정은 앞선 포스팅에서 설명한 index관련 매서드들을 참고하도록 하자.
# 특정 Column을 정보만 DataFrame 변환하기: usecols = ["column 위치1", "column 위치2" ] 또는 ["column명1", "column명2" ]
데이터의 특정 행만 추출하여 DataFrame화 하는 방법을 앞서 알아보았는데, 그럼 Column에 대해서도 동일하게 진행할 수 있는 매서드가 있을까?(당연히 없을 수가 없겠지만...) usecols라고 불리는 인자가 이 역할을 담당하는데, 이 값은 List형태의 값으로 지정 가능하며, List의 값으로 Column의 위치(순번) 또는 column명을 지정할 수 있다.
필자는 CSV 데이터 중, ID, 나이, 연봉만 추출하여 저장하려 한다.

위와 같이 필자가 지정한 정보에 대해서만 DataFrame으로 변환된 것이 확인된다. Column의 이름 또는 위치를 지정하기 위해서는 데이터 내에 저장되는 값에 대한 정보를 미리 인지하고 있어야 하는데, 이는 데이터 수집/추출/정제와 관련된 부분이므로 이 포스팅에서는 다루지 않는다(다루게 될 경우, 별도의 내용으로 포스팅하겠다...만, 자료를 어디서 추출하지??).
참고로, index_col 인자와 동시에 사용하는 경우, index_col 인자는 반드시 usecols 내에 포함된 column명을 사용해야 한다. 그렇지 않은 경우, index_col의 값을 인식할 수 없다는 에러가 나타나게 된다.

2. 텍스트 파일 불러오기 : pandas.read_csv("파일명")
필자는 위에서 사용한 CSV 파일을 메모장에서 열어, 모든 콤마(,)를 스페이스 4칸으로 변경하였다. 그리고 파일명은 유지한 채, 파일 확장자만 txt로 저장하였다.

텍스트 파일을 읽는 것도 to_csv() 매서드를 사용하면 된다. 다만, 텍스트파일의 경우, CSV와 달리 위의 예시처럼 공백이나 탭 등의 구분자로 구분되어 저장된 파일도 존재할 수 있기 때문에, 이들 구분자를 이용하여 DataFrame으로 변환하는 방법에 대해 알아보려 한다.
read_csv는 csv 파일 외에 txt 파일도 읽을 수 있는 매서드다. 그리고 txt 파일의 데이터를 불러올 때, 구분자가 콤마(,)가 아닌 다른 값으로 지정된 경우, 해당 구분자를 인식하여 각각의 값들을 Column명에 맞게 배치하고 DataFrame으로 변환하는 기능을 제공한다. 이 때 구분자를 인식하는 인자는 sep을 사용하며, sep 의 값은 인식할 구분자 값을 지정해주면 된다.
필자의 경우, txt 파일을 스페이스 4칸으로 구분자 정의를 했으므로, sep 인자값을 스페이스 4칸으로 지정하여 데이터를 호출해보았다.

보통 텍스트 파일의 경우, TSV(Tab Seperated Values)인 경우 사용하는 듯 한데, CSV가 워낙 압도적이다보니 저 sep 인자를 변경하여 쓸 일이 자주 없는 듯 하다(to_csv() 매서드는 sep의 기본값이 콤마(,)다).
3. 엑셀 파일 불러오기 : pandas.read_excel("파일명")
엑셀 파일의 호출 역시 이전의 read_csv와 매우 유사하다. 하지만 한 가지 다른 점이 있다. excel의 경우 여러 시트(sheet)가 하나의 파일을 구성할 수 있으며, 각 시트가 각기 다른 데이터를 포함하는 경우가 대부분이다. pandas의 read_excel() 매서드는 이 시트들의 이름을 지정하여 특정 시트의 데이터를 호출하는 것이 가능하다.
시트명을 지정하는 인자는 sheet_name이다. 특이하게도 CSV 역시 시트로 구분하여 저장할 수는 있지만, 이 인자를 지원하지 않는다. 따라서 엑셀 파일에서만 사용이 가능하다.
필자는 CSV의 데이터 내용을 복사하여 Excel 파일에 옮긴 뒤, 시트명을 Member_Info로 지정하고 저장하였다. 따라서 다음과 같이 코드를 사용하면 Member_Info의 데이터가 DataFrame으로 호출되게 된다.

read_excel() 매서드 역시, read_csv() 와 마찬가지로, index_col, usecols 등과 같이 DateFrame 생성에 공통적으로 사용되는 인자들을 지원한다.
II. DataFrame을 파일로 저장하기
1. DataFrame 값을 특정 파일명으로 저장하기: to_csv("파일명"), to_excel("파일명")
이제 DataFrame으로 변환하면서 가공한 정보들을 파일로 저장하는 방법에 대해 알아보자. 파일 저장과 관련된 매서드들은 읽기 매서드 명의 read 대신 to를 쓰면 된다. 따라서 CSV 파일은 to_csv, Excel 파일은 to_excel을 사용하면 된다. 이번 실습에서, 필자는 CSV 파일의 데이터 중, ID, 나이, 연봉 정보만 추출하여 파일로 저장해보려 한다.

to_csv(), to_excel()의 경우, 인자값을 지정하지 않고 사용하는 경우, 결과가 고스란히 화면에 출력된다.

그러나 인자값으로 저장하고자 하는 파일명과 확장자명을 지정해주면, 매서드 결과들이 해당 파일로 저장된다.

텍스트의 경우, sep 인자를 사용하면 comma 대신 다른 구분자로 데이터를 저장하는 것도 가능하다.

엑셀 역시, sheet_name을 사용하면, 특정 시트명으로 데이터를 저장할 수 있다. 단, to_excel() 매서드만으로는 하나의 파일에 두 개 이상의 시트를 생성하는 것이 불가능한데, 이를 가능하게 하려면, Pandas의 ExcelWriter라는 매서드를 사용해야 한다고 Pandas 매뉴얼에 작성되어 있다.

# 기본 Index 비활성화 형태로 파일 저장하기: index = False
필자가 파일을 저장할 때, Emp ID값을 Index_col 인자값으로 지정하여 저장을 진행했다. 하지만 이렇게 index_col 값을 지정하지 않은 경우, DataFrame의 기본 Index 값이 파일에 저장되게 된다. 만약 Index 정보를 없애고 저장하고 싶다면, 인자 index를 False로 지정해주면 된다.

index 값을 True(기본값)으로 지정한 결과와 비교해보자.

# Column명 행을 제외한 데이터만 파일 저장하기: header = False
to_csv(), to_excel() 등의 매서드는 header라는 인자를 기본값 True로 가지고 있다. 이 인자는 DataFrame의 Column 명이 명시된 행을 출력하는 기능을 가지는데, 이 값을 False로 지정하면, 파일 저장 시, Column 명이 제외되게 된다.
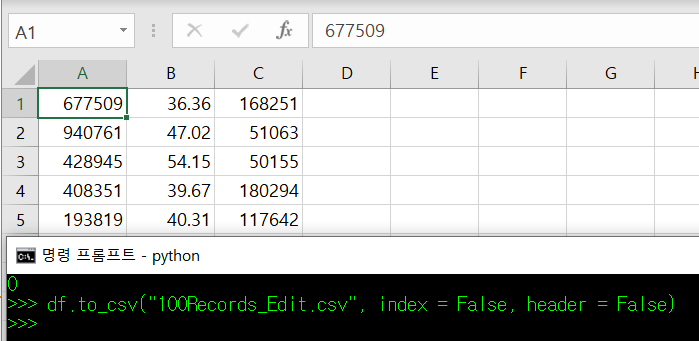
# 데이터를 특정 파일에 추가하기: mode = "a"
to_ () 매서드로 데이터를 저장하는 경우, 기본적으로 모든 파일에 덮어쓰기가 진행된다. 그 이유는 to_ () 매서드 인자의 mode 값 때문인데, 이 인자가 기본값으로 "w"로 지정되어 있기 때문이다. 마치 파이썬으로 파일을 쓸 때 "a" 또는 "w"로 구분하듯이 말이다.

위와 같이 코딩하는 경우, 첫 df 결과는 "100Records_Edit.csv" 파일에 덮어쓰기 된다. Column 명이 유지가 된 상태로 말이다. 그리고 두 번째 코드는 Column값 없이 데이터 값만 "100Records_Edit.csv" 파일에 추가된다.

다음 포스팅에서는 DataFrame에 포함된 데이터 정보를 기본 통계학과 함께 알아보는 방법에 대해 작성하려 한다.
Fin.
'Python > Python DataAnalysis' 카테고리의 다른 글
| [Python Data Analysis] 8. DataFrame 데이터 슬라이싱 (0) | 2021.11.17 |
|---|---|
| [Python Data Analysis] 7. DataFrame 데이터 정보 확인 및 기본 통계 (0) | 2021.11.14 |
| [Python Data Analysis] 5. DataFrame, Index 관련 매서드 (0) | 2021.11.03 |
| [Python Data Analysis] 4. DataFrame 객체 (0) | 2021.11.02 |
| [Python Data Analysis] 3. Pandas 모듈 (0) | 2021.09.20 |




댓글