이번 포스팅에서는 DataFrame으로 변환한 정보들의 개괄적인 내용에 대해 알아보려 한다. DataFrame의 index, column이 무엇으로 구성되어 있는지, 아니면 DataFrame의 크기는 어떤지 등에 대해 아는 것만으로도 분석하려는 데이터에 대한 대략적인 이해가 가능하기 때문이다.
본 포스팅에서는 조금 더 깊게 들어가, 숫자 형태로 구성된 특정 필드값에 대해 기본적인 통계 개념을 적용할 수 있는 매서드와 클래스 변수들도 확인해보려 한다.
오늘의 포스팅에서 확인하려는 내용은 아래와 같다.
[ 데이터 정보 확인 ]
# pandas.DataFrame.index : DataFrame의 Index 정보 표시
# pandas.DataFrame.columns : DataFrame의 column(필드) 정보 표시
# pandas.DataFrame.values : DataFrame에 기록된 데이터 정보 표시
# pandas.DataFrame.shape : DataFrame의 크기 정보 표시
[ 기본 통계 활용 매서드 ]
# pandas.DataFrame["column명"].descrbe(): DataFrame 데이터 중 계산 가능한 값만 추출하여 평균, 최대, 최소치 값 등
출력. 특정 필드값에 대한 통계값 출력 지원
# pandas.DataFrame["column명"].count() : DataFrame의 특정 필드의 통계 수 정보 표시
# pandas.DataFrame["column명"].max() : DataFrame의 특정 필드의 최대값 정보 표시
# pandas.DataFrame["column명"].min() : DataFrame의 특정 필드의 최소값 정보 표시
# pandas.DataFrame["column명"].nlargest(n) : DataFrame의 특정 필드 중 최대값 n개 표시
# pandas.DataFrame["column명"].nsmallest(n) : DataFrame의 특정 필드 중 최소값 n개 표시
# pandas.DataFrame["column명"].sum() : DataFrame의 특정 필드값의 총합 정보 표시
# pandas.DataFrame["column명"].mean() : DataFrame의 특정 필드값의 평균값 정보 표시
# pandas.DataFrame["column명"].median() : DataFrame의 특정 필드값의 중간값 정보 표시
# pandas.DataFrame["column명"].mad() : DataFrame의 특정 필드값의 평균 편차 정보 표시. 편차는 절대값(Abs) 사용.
# pandas.DataFrame["column명"].var() : DataFrame의 특정 필드값의 분산 정보 표시(N-1 정규화)
# pandas.DataFrame["column명"].std() : DataFrame의 특정 필드값의 표준 편차 정보 표시(분산^(1/2))
# pandas.DataFrame["column명"].skew() : DataFrame의 특정 필드값이 치우친 정도(Skewness)를 표시
# pandas.DataFrame["column명"].kurtosis() : DataFrame의 특정 필드값의 정규 분포를 벗어나는 이상치 수량 정보 표시
# pandas.DataFrame["column명"].unique() : DataFrame의 특정 필드값의 고유값 정보만 표시
# pandas.DataFrame["column명"].value_counts() : DataFrame의 특정 필드값의 고유값 사용 수량 정보 표시
# pandas.DataFrame["column명"].nunique() : DataFrame의 특정 필드값의 고유값 갯수 정보만 표시
# pandas.DataFrame["column명"].duplicated() : DataFrame의 특정 필드값이 중복되는 값을 가지는지 여부를 표시
# pandas.DataFrame["column명"].drop_duplicates() : DataFrame의 특정 필드값 중 중복값은 제외하고 표시
이번 포스팅에서는 단순히 통계학적으로 사용할 수 있는 매서드에 대한 설명으로 끝나지 않고, 해당 매서드의 배경이 되는 통계학 개념에 대해 필자가 나름대로 정리한 내용도 덧붙이려 한다. 따라서 내용이 무지 길다(스압 주의). 필자가 독학으로 정리한 내용이기 때문에 정확하지 않은 내용이 있을 수 있음은 감안하자.
I. 데이터 정보 확인
이전 포스팅에서 사용한 CSV 자료를 계속해서 사용한다. 해당 파일을 read_csv() 하여 DataFrame화 하자.
1. DataFrame의 Index 정보 확인: pandas.DataFrame.index
DataFrame은 행(row)과 열(column)로 이루어져 있으며, 행에 작성된 정보들을 구분하는 가장 주요한 column값들을 Index로 지정한다. 필자가 이전 포스팅에서 사용한 CSV 파일 자료를 토대로 보자면, 각 인적 사항이 작성된 행들을 구분하는 고유 값들은 "Emp ID" 필드에 명시되어 있다.
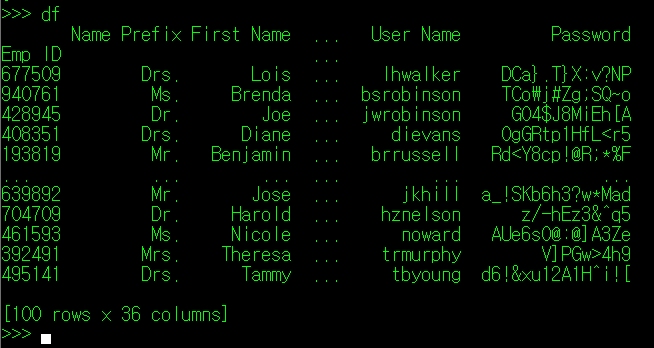
그럼, Index를 구성하는 값이 어떤 것이 있는지 알 수 있는 방법이 있을까? 왜냐하면, 특정 ID 값을 가지는 사람에 대한 정보를 찾아야 하는데, 해당 ID 값이 있는지 없는지는 알아야 할 필요가 있기 때문이다. 너무 당연하게도 DataFrame은 이러한 기능을 index라는 DataFrame 클래스 객체로 제공하고 있다.
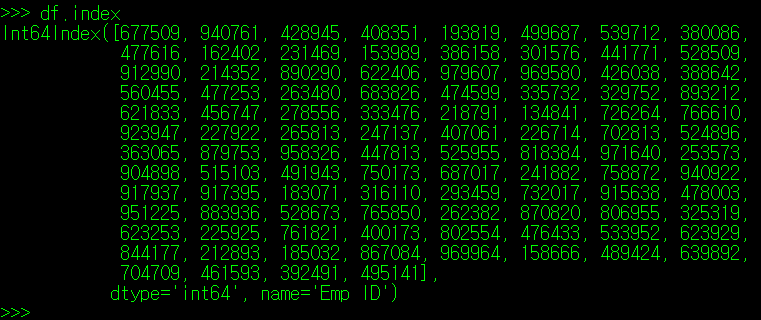
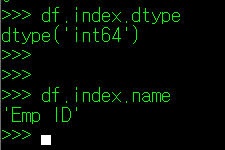
df.index는 특이하게도 정의된 값 외에 dtype과 name 정보도 함께 출력하는데, dtype은 index 값의 타입을, name은 index를 지칭하는 column명을 의미한다. 이들 값 역시 별도의 클래스 변수로 호출이 가능하다. dtype의 경우 index.dtype을, name의 경우 index.name을 사용하면 된다.
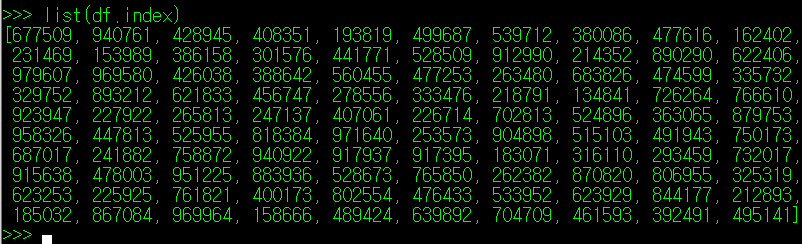
df.index를 type() 함수로 확인해보면 pandas에서 정의한 변수의 한 종류로 나타하며, 해당 값들을 List화 하면 아래와 같이 index에 정의된 모든 값들을 List 형태로 출력하는 것도 가능하다.
2. DataFrame의 Column 정보 확인: pandas.DataFrame.columns
DataFrame의 column에 대해서도 동일한 작업을 진행할 수 있다. index 대신 columns 클래스 변수를 사용하면 DataFrame의 column 변수들이 df.index와 동일한 포맷으로 출력된다.
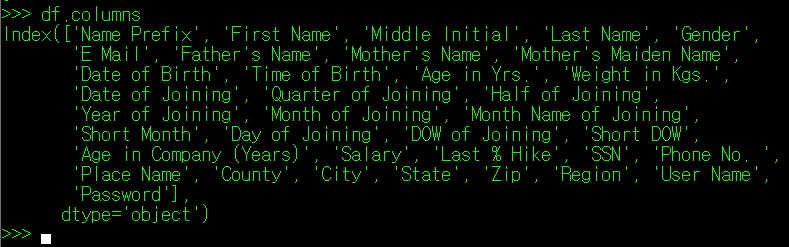
index와의 차이점이라면, (너무 당연하게도)Column의 이름이 없다는 것인데, 이 때문에 column 뒤에 .name을 입력할 경우 아무 값도 출력되지 않게 된다. 물론, df.columns.name으로 이 값을 지정할 수 있긴 하다.
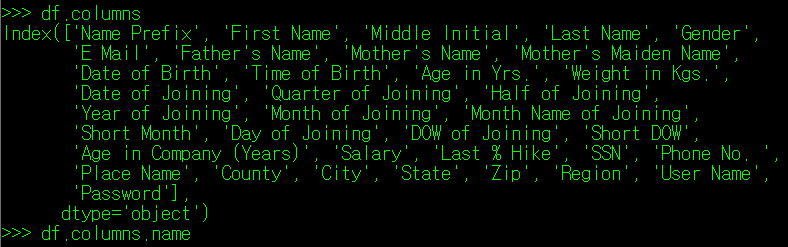
마찬가지로 columns 결과 역시 List화 하는 것이 가능하다.
3. DataFrame의 데이터값에 대한 정보 확인: pandas.DataFrame.values
DataFrame의 index 및 columns에 대한 정보가 출력된다면, 가장 중요한 데이터에 대한 내용도 출력이 가능할까? 당연히 가능하다. values라는 클래스 변수가 그 정보를 담고 있다.

values의 결과는 array라는 타입으로 출력되는데, 여기서 Array는 일종의 나열이 필요한 자료들을 저장하는 타입들(List, Tuple 등)을 일컫는다고 보면 된다. values의 결과를 자세히 보면, 행 하나 당 List 하나로 묶에 있으며, 행의 List 내에는 행이 가지는 값들이 저장되어 있다. 그리고 각 행에 해당하는 List들은 2차 List에 의해 묶여 저장되고 말이다.
따라서 이 values의 결과도 List화 한 뒤, List 사용법과 동일하게 자료를 탐색하면 된다. 가령 필자가 마지막 줄의 데이터만 출력하고 싶다면, 아래와 같이 코딩하면 된다.

마지막 결과가 Tammy라는 사람에 대한 인적 정보가 나타나는 것을 확인할 수 있으며, iloc으로 마지막 데이터의 이름 정보를 확인한 결과, 동일하게 Tammy라는 이름이 출력되는 것을 확인할 수 있다.
4. 내가 다루는 DataFrame의 크기는 얼마나 큰 것일까? pandas.DataFrame.shape
데이터 파일로부터 DataFrame을 변환하고 나면, 내가 만든 데이터의 크기가 궁금해질 때가 있다. 물론 그 양이 컴퓨터가 처리할 정도의 범위 내라면 단순히 df를 입력하여 마지막에 뜨는 정보를 확인하면 되지만
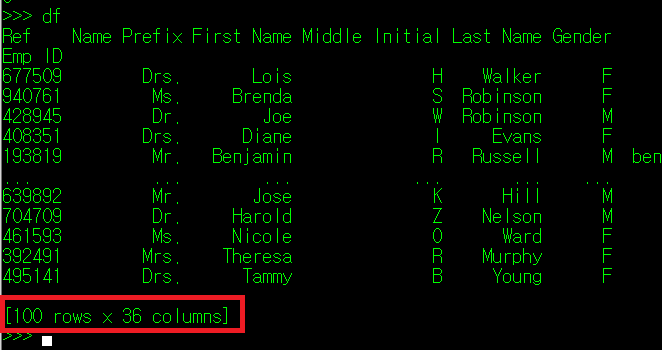
실제 업무에서 추출하는 데이터 양이 무진장 많기 때문에 단순하게 df 명령어를 썼다가 저 모든 데이터가 화면에 출력되는 것을 하염없이 기다리고 있어야 할 수도 있다. 그것도 데이터 크기를 확인하려는 단순 작업 때문에 말이다.
DataFrame의 shape는 모든 데이터의 화면 출력 없이 DataFrame의 크기 정보만 갈무리해준다.

shape의 결과는 Tuple로 반환되는데, Tuple 내에는 DataFrame의 행, 열 숫자가 표시된다.
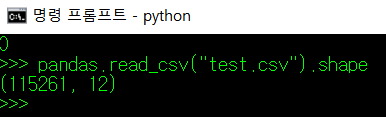
참고로 현재 필자가 업무 중에 다루는 데이터 파일의 크기가 위와 같다. 저 파일의 내용을 화면에 출력하려고만 해도 약 30초라는 시간이 걸린다. 그러나 shape 변수를 사용하면 해당 데이터의 크기만 출력하기 때문에 불필요한 시간이 소요되는 것을 방지할 수 있다.
II. 데이터 기본 통계로 분석하기
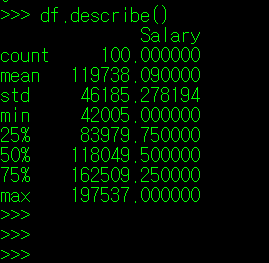
1. 특정 column의 데이터 정보 확인하기: pandas.DataFrame.describe()
DataFrame은 descibe()라는 매서드를 통해, DataFrame이 지니는 값들에 대한 개괄적인 내용을 출력한다.
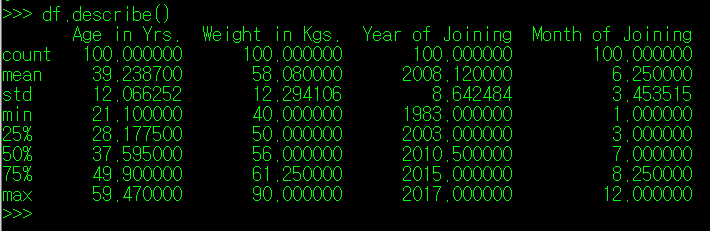
좌측의 항목을 보면 알 수 있듯이, 데이터 수, 평균값 표준 분산 등등에 대한 내용이 출력된다. 하지만 DataFrame에서 직접 describe() 매서드를 사용할 경우, column의 값들이 int, float인 자료들에 대해서만 개괄적인 내용을 출력해준다. 각 Column에 대해 세부적인 내용을 보고 싶다면 DataFrame의 Column까지 명시해주는 것이 좋다.
(1) 계산 불가한 Column에 대한 개괄 내용
먼저, 계산이 가능한 숫자가 아닌 문자열로 구성된 Column에 대해 describe() 매서드를 사용해보자. column 이름 중 "Name Prefix"가 있는데 이는 사람의 호칭에 대한 내용을 저장한 Column과 관련이 있다. 필자는 이 컬럼만 별도로 선정하여 describe() 매서드를 사용하였고, 아래와 같은 결과를 얻었다.
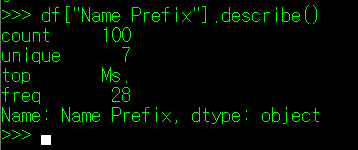
출력된 결과를 하나씩 보자.
① DataFrame["Column명"].count()
먼저 Count는 해당 Column이 가지는 데이터의 수를 나타낸다. 별다르게 설명할 것이 없으니 넘어가자.
② DataFrame["Column명"].unique()
다음으로 Unique 값인데, 이는 Column이 가지는 값의 종류를 나타낸다. 실제 데이터에는 Name Prefix가 아래의 7개 값으로만 지정되어 있으며,

중복되는 값을 모두 제외하여 남은 값들의 수를 의미한다고 보면 된다.
③ DataFrame["Column명"].value_counts()
Top은 Unique의 값들 중, 최빈값(가장 많은 비율을 차지하는 값)을 나타내며, freq는 frequency의 약어로, Top으로 지정된 값이 DataFrame의 해당 Column에서 등장한 횟수를 나타낸다.
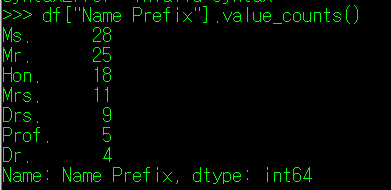
DataFrame에서 지원하는 value_counts() 매서드들을 사용하면 각 column의 Unique 값이 몇 번 사용될 수 있는지 알 수 있으며, 위의 결과에서는 Ms. 호칭이 28번 사용되어 Top과 freq 값과 동일함을 확인할 수 있다.
(2) 계산 가능한 Column에 대한 개괄 내용
다음으로 계산 가능한 Column에 대해 describe() 매서드를 사용해보자. 숫자로 구성된 것 중 가장 눈에 들어오는 "Salary"에 대해 describe()를 진행해보려 한다.
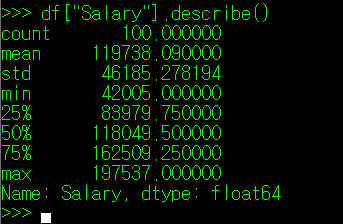
Salary의 describe() 결과를 보면 바로 앞에서 보았던 "Name Prefix"와는 다른 양상을 띈다. 계산이 가능한 값으로 구성되어 있기 때문에 describe() 매서드를 사용하면, 데이터의 수 뿐만 아니라 평균(mead), 표준 편차(std), 최소(min), 최대(max) 값 등을 일괄 계산하여 출력해준다. 해당 값들은 DataFrame의 매서드를 이용하여 개별적으로 출력할 수도 있는데, 이 매서드들은 필자가 소제목으로 구분을 하려한다.
** 필자가 df를 pandas.read_csv("100Records.csv", usecols="Salary")로 변경한 값을 아래에서 사용한다.
① DataFrame["Column명"].count()
앞서서도 설명한 내용인데, 가장 첫 행에 나타나는 count 는 해당 column의 데이터 수를 나타낸다. 이는 계산 불가한 값을 가지는 column과 동일한 내용이다.
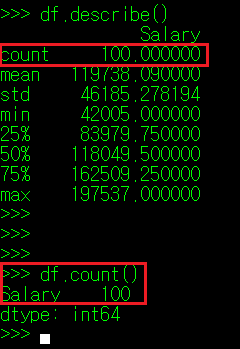
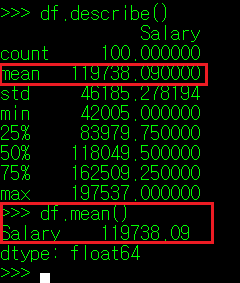
② DataFrame["Column명"].mean()
두 번 째 행에 나타나는 mean은 사전 상 '평균'이라는 의미를 가지며, 수로 구성된 모든 column 데이터 값의 평균을 화면에 표시해 준다. 통계학에서 평균의 종류가 상당히 많지만, mean() 매서드는 산술 평균(총합을 데이터 수로 나눈 값)을 화면에 출력한다.
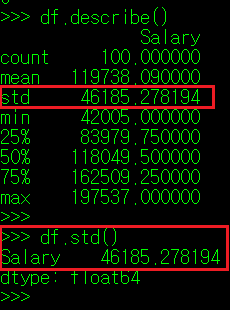
③ DataFrame["Column명"].std()
세 번 째 행에 나타나는 std는 Standard Deviation의 준 말로, 표준 편차를 나타낸다. 표준 편차란, 측정 또는 수집한 데이터가 얼마나 퍼져있는지를 측정하는 수치인데, 수식으로 나타내면 분산의 제곱근과 같은 말이다. 분산은 편차, 즉 각 측정값이 기준값으로부터 얼마나 떨어져 있는지 나타내는 수치를 제곱한 값을 합한 뒤 평균으로 나눈 값이다. 수식으로 나타내면 아래와 같다.
----------------------------------------------------------------------------------------------
** 편차 = 측정값 - 기준값
** 분산 = (각 측정값의 편차^2) 의 평균 (단, 표본집단의 경우 평균으로 나눌 때 N-1값을 사용한다)
** 표준 편차 = 분산^(1/2)
----------------------------------------------------------------------------------------------
이를 확인하기 위해 새 DataFram을 만들어 테스트해보자. 필자는 1부터 10까지 숫자 12개를 데이터 값으로 넣을 것이고, 이들 값을 무작위로 아래와 같이 배정했다.

이들 값의 평균은 4.4이며, 각 데이터의 편차 제곱값을 합한 뒤 평균을 낸 값, 즉 분산은 10.49가 나온다. 이 값을 제곱근하면 3.239라는 값이 나오며, 실제 describe()로 확인하더라도 동일한 값이 나오는 것을 알 수 있다.
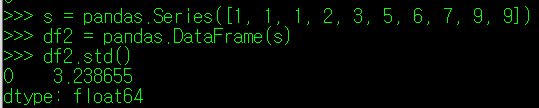
표준편차는 뒤에서 살펴볼 평균절대편차와 같이 데이터가 특정값으로부터 얼마나 퍼져있는지를 확인하는 척도이다. 이 둘의 개념이 나누어진 배경에 대해서는 조금 아래에서 설명한다.
④ DataFrame["Column명"].min(),
DataFrame["Column명"].quantile(소숫점 백분위),
DataFrame["Column명"].max()
네 번 째 행 부터 나타나는 값은 순서대로, 최소값, 1사분위 값, 2사분위값, 3사분위값, 최대값이다.
통계에서 백분위 값, 그리고 사분위수라는 개념이 존재하는데, 이는 전체 통계 표본을 오름차순으로 순차 나열했을 때, 범위 내 특정 백분율에 해당하는 지점의 값을 나타낸다고 보면 된다. 예를 들어, 숫자 1, 2, 3, 4. 5가 통계 표본으로 존재 시, 3은 백분위 50(2사분위)에 해당하는 값이고, 2와 4는 각각 25(1사분위), 75%(3사분위)에 해당하는 값이다.
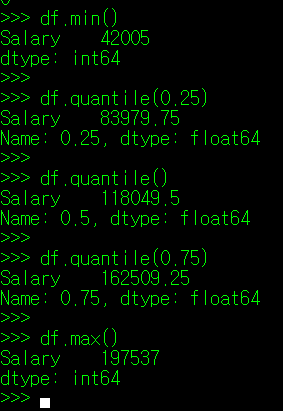
quantile() 매서드는 인자를 기본값으로 사용할 경우 2사분위(중위값)을 표시하나, 인자로 백분위 값(0~1)을 정의해주면 해당 백분위에 위치한 값을 계산하여 화면에 출력해준다.
참고로 사분위값을 구하는 공식은 아래와 같다.
-------------------------------------------------------------------------------------------------
** 2 사분위 값(중위수) 공식
-> 통계 표본 수(N)가 짝수일 때: 0.5 * (N + 1) 번째에 위치한 값
-> 통게 표본 수(N)가 홀수일 때: 0.5 * (N + 1) 번째 및 0.5 * (N+1) 번째 위치 값의 평균
=> s = 1, 2, 3, 4, 5, 6, 7 : 2 사분위 값 = 4 (4번째 위치한 값)
=> s = 1, 2, 3, 4, 5, 6 : 2 사분위 값 = 3.5(3.5 번째 위치한 값)
** 1 사분위 값 공식
-> 첫 번째 값과 중앙값 사이 통계 표본 수를 N이라 할 때, (N + 1) * 0.5 번째에 위치한 값.
=> s = 1, 2, 3, 4, 5, 6, 7 : 1사분위 값 = 2.5(2.5번 째에 위치한 값으로 2와 3의 평균 값)
=> s = 1, 2, 3, 4, 5, 6 : 1사분위 값 = 2.25( 4.5 * 0.5 번째 위치한 값으로 2.25번째에 위치한 값)
** 3 사분위 값 공식
-> 중앙값과 마지막 값 사이 통계 표본 수를 N이라 할 때, 뒤에서 '((N + 1) * 0.5) + 1'번째에 위치한 값.
=> s = 1, 2, 3, 4, 5, 6, 7 : 3사분위 값 = 5.5(5.5번 째에 위치한 값으로 5와 6의 평균 값)
=> s = 1, 2, 3, 4, 5, 6 : 3사분위 값 = 4.75(뒤에서 2.25 번째 위치한 값)
위치가 정수가 아닌 소숫점으로 나오는 경우 아래와 같이 계산한다.
N.5 = > N과 N+1의 평균값
N.25 => 1사분위 값의 경우: N, N+1번째 값의 평균값 - (N, N+1번째 값의 차이 * 0.25)
=> 3사분위 값의 경우: N, N-1번째 값의 평균값 + (N, N-1번째 값의 차이 * 0.25)
-------------------------------------------------------------------------------------------------
참고로 describe() 매서드 사용 시, 인자로 percentiles을 사용하면 특정 백분위수의 값을 출력하는 것이 가능하다. 사용법은 아래와 같다.
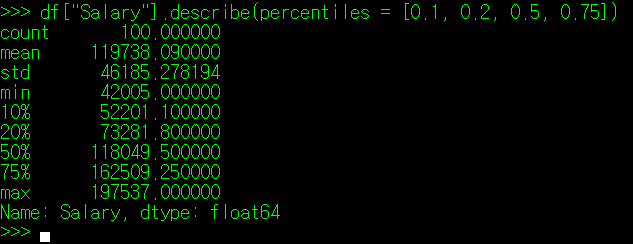
위와 같은 방식으로 각 Column에 기록된 값에 대해 대략적인 통계 정보를 확인할 수 있다.
2. 특정 필드 내 데이터 중 최소/최대값 N개 찾기: pandas.DataFrame["Column명"].nlargest/nsmallest(n)
DataFrame["Column명"]의 매서드 중, nlargest(), nsmallest()라는 매서드가 있다. 이름에서도 알 수 있듯이, 이들 매서드는 Column 내 데이터 중 최소/최대값 N개를 출력하는 역할을 한다.
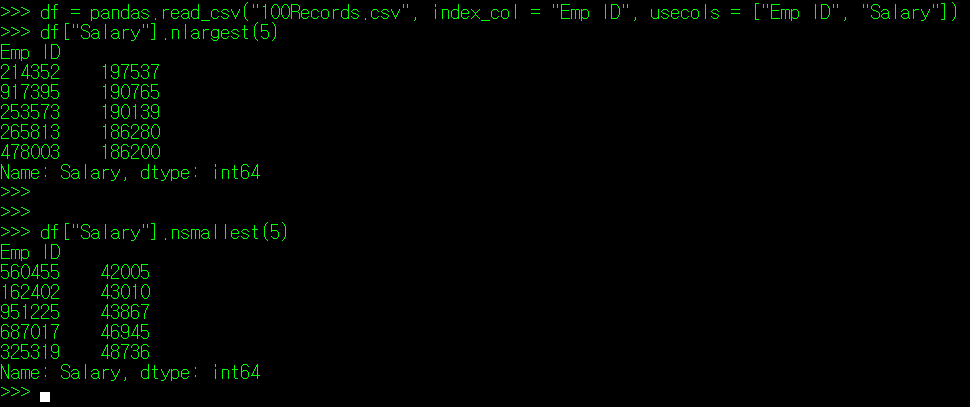
필자는 df 변수를 조금 수정하여, 데이터 파일로부터 직원 ID와 연봉 정보만 별도로 추출하고, 최고 / 최저 연봉 수령자 5명의 정보를 위와 같이 출력했다(필자도 돈 많이 벌고싶다). 엑셀도 내림차순 정렬 기능을 제공하지만, 엑셀의 경우 내림차순을 사용하면 데이터의 위치 변환으로 인해 종종 저장 중에 데이터가 뒤틀리거나 잘못 저장되는 경우가 있어 불편한 점이 있지만 Pandas를 사용하면 단순 명령어 몇 줄로 최대, 최소 값 N개의 확인이 가능해진다. 원본 데이터 파일을 건드리지 않고 말이다.
3. 특정 필드 내 데이터 합 구하기: pandas.DataFrame["Column명"].sum()
데이터의 합을 구하는 매서드는 sum()이다. 이는 엑셀의 총합 함수와 동일하기 때문에 큰 설명이 필요없을 듯 하다.
필자는 회사에서 전 직원들에게 주는 연봉 총액이 얼마나 되는지를 아래와 같이 확인할 수 있다.

4. 특정 필드 내 데이터 중위값 확인하기: pandas.DataFrame["Column명"].median()
pandas는 quantile() 매서드에 인자를 지정하지 않고 사용할 경우, 중위값 데이터를 확인할 수 있는데, 이와 동일한 역할을 하는 median()이라는 매서드도 존재한다. 이 매서드는 quantile과 달리, 2사분위 중위값만 출력하므로 백분위 수를 인자에 지정할 수 없다.

참고로 이 중위값이라는 개념은 평균과는 동일한 개념이 아니다. 평균은 모든 데이터의 합을 데이터 수 만큼 나눈 값이고, 중위값은 데이터 중 한 가운데 위치한 값(실제 값)을 의미한다. 예를 들어 1이 19개, 10이 1개로 구성된 데이터는 중위값이 1이지만 평균은 1.45이다.
5. 특정 필드 내 데이터의 평균 편차 확인하기: pandas.DataFrame["Column명"].mad()
mad() 매서드에 대해 설명하려면 통계학에서 말하는 편차에 대해 정리를 하고 넘어갈 필요가 있다.
통계학에서 데이터가 얼마나 퍼져있는지를 확인하는 지표로 편차와 분산이 있다. 먼저 편차부터 살펴보자.
편차는 말 그대로 어떠한 값으로부터 실제 데이터가 얼마나 떨어져있는지를 나타내는 값이다.
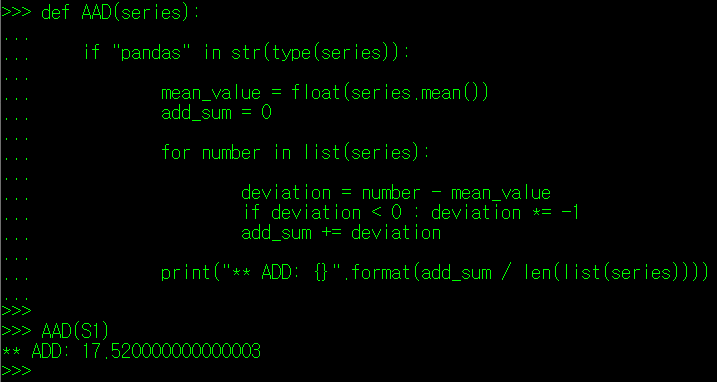
편차는 다시 세부적으로 평균 편차(Average Deviation: AD)와 평균 절대편차(Average Absolute Deviation: AAD), 중위값 편차(Median Deviation: MD), 중위값 절대 편차(Median Absolute Deviation: MAD) 등으로 나뉜다.
평균 편차는 각 데이터가 퍼진 정도를 확인하는 기준점을 평균값으로 잡은 편차다. 예를 들어, 관측값 1, 2, 3, 4, 5가 있다면, 각 데이터의 편차는 -2, -1, 0, 1, 2가 되며, 이들의 평균인 0이 평균 편차가 된다. 지금의 예시에서도 확인이 가능한 내용이지만, 어떠한 데이터라도 평균 편차는 0이 나올 수 밖에 없다. 필자가 극단적으로 1, 1, 1, 1, 1, 1, 1, 1, 10이라는 데이터를 가지고 평균 편차를 구하더라도 평균 1.9를 기준점으로 하는 편차의 평균은 0이 될 수 밖에 없다.
* {(-0.9) * 9 + 8.1} / 10 = 0
따라서 평균 편차로는 데이터값이 얼마나 퍼져있는지 확인하기가 어렵다. 그래서 나온 개념이 평균 절대 편차(AAD)이다.
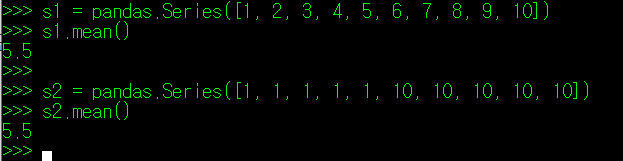
위의 두 개의 데이터를 보자. 하나는 1부터 10까지 순차적으로 정의된 데이터이고, 다른 하나는 1과 10으로 양극화된 데이터이다. 두 데이터 모두 평균은 5.5 이다. 이들 데이터의 평균 절대편차를 구하면 아래와 같다.
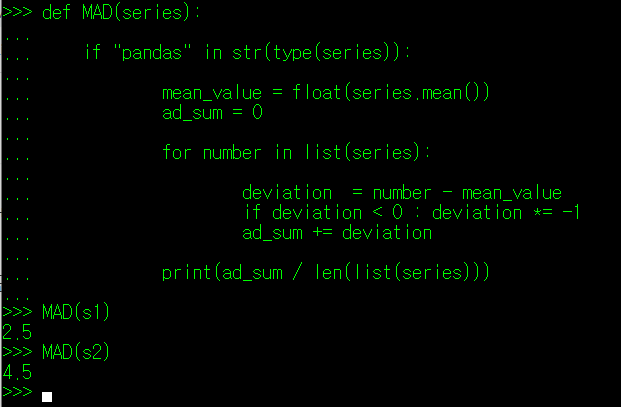
두 데이터를 비교해보면 양 극단으로 나뉘어진 S2 데이터가 평균절대편차 값이 훨씬 큰 것을 알 수 있다. 위의 예시에서도 알 수 있듯이, 전체적인 값이 한 군데에 집중되어 있을 경우 평균 절대 편차는 0에 가까워지며, 반대인 경우 값이 증가한다. 이렇듯 특정 값에 대한 평균 편차를 통해 데이터들이 평균으로부터 얼마나 퍼져 있는지를 확인할 수 있다.
pandas의 DataFrame 역시, 계산 가능한 값으로 구성된 필드에 대해서 평균 표준 편차를 제공하여 데이터들이이 평균값으로부터 얼마나 분산되어 있는지를 확인할 수 있다. 이와 관련된 매서드는 mad()가 있다.
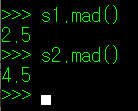
위에서 필자가 함수를 사용해 계산한 평균절대편차와 동일한 값이 나타남을 확인할 수 있다.
pandas에서 DataFrame이나 Series에 대해 mad() 값 사용 시, 유의할 점이 있는데, mad() 매서드는 통계학에서의 AAD, 즉 평균 절대 편차를 의미한다는 것이다. 사용 시 헷갈리지 않도록 주의하자.

6. 특정 필드 내 데이터의 분산과 표준편차 확인하기: pandas.DataFrame["Column명"].var()
pandas.DataFrame["Column명"].std()
앞서 설명한 평균절대편차와 마찬가지로, 표준편차역시 데이터의 분산 정도를 확인할 수 있는 통계값이다. 평균절대편차와 달리, 표준편차는 평균절대편차에 제곱수를 한 총합의 평균을 다시 제곱근으로 보정한 값이다.
** 표준편차 = {SUM( 편차^2 ) / (N - 1)} ^(1/2)
평균절대편차만으로도 충분히 데이터가 분산된 정도의 확인이 가능한데, 왜 굳이 귀찮게 제곱을 하고 다시 제곱근을 적용하는 것일까? 이를 위해, 데이터 표본을 대표하는 대표값이라는 개념에 대해 짚고 넘어가야 한다. 아래의 데이터를 보자.
S1 = [1, 1, 1, 2, 2, 3, 4, 5, 5, 100]
위의 데이터를 pandas의 Series(1행 데이터)로 변환한 뒤, 평균과 중앙값을 구해보자.
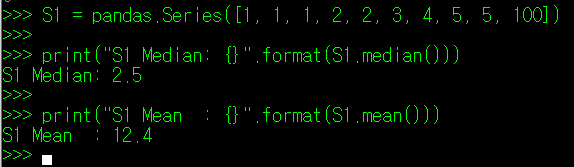
자, S1 데이터들을 대표하는 값은 무엇일지 생각해보자. 평균값을 보면, 극단적인 100이라는 값으로 인해 나머지 값들에 비해 대표값이 뻥튀기가 심하게 된 느낌이 든다. 마치 매년 언론에서 발표하는 전국민 연봉 평균을 보는 것과 같이 말이다. 위와 같이 극단적인 값이 포함된 데이터에서는 중위값인 2.5가 오히려 전체 데이터를 조금 더 상징적으로 나타낸다고 볼 수 있다. 왜 그럴까?
다시 절대편차로 넘어와보자. 절대편차는 평균절대편차(AAD)와 중위값절대편차(MAD)로 나눌 수 있는데, 이번에는 두 값을 출력하여 비교해보도록 하자.
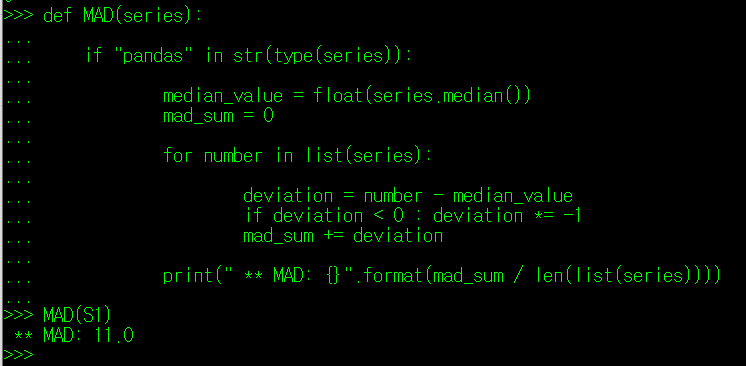
통계학에서는 전체 데이터에 대해서 편차가 최소값으로 나타나는 부분이 전체 데이터를 가장 잘 설명한다고 보며, 이에 따라 평균값보다는 중위값이 위의 데이터를 대표하는 값이 될 수 있다. 실제로 중위값이 아닌 다른 값을 기준으로 절대편차를 구하면 평균절대보다 작은 값이 나타나지 않음을 알 수 있다.
다음으로는 평균을 중심으로 나름 균등하고 대칭적으로 분산된 데이터인 S2에 대해 알아보자.
S2 = [1, 1, 3, 4, 5, 7, 7, 8, 9, 11]
마찬가지로 해당 데이터에 대해서도 평균값과 중앙값을 구한 뒤, 각 기준값에 대한 절대편차를 구해보자.
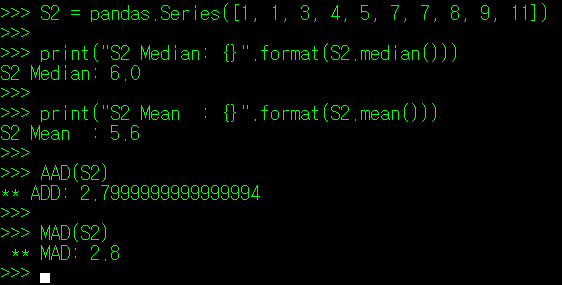
이번에는 아주 근소한 차이이긴 하나 S2를 대표하는 값은 평균값이 조금 더 적합하다. 그리고 실제로 절대 편차 기준값을 평균값이 아닌 다른 값으로 지정했을 때, 평균값을 지정한 경우보다 항상 큰 값이 나타난다.
자, 이제 데이터의 스케일을 많이 키워보자. 데이터의 수가 대략 100만개라고 가정하면 정말 극단적인 데이터가 아닌 이상 데이터의 분포는 평균을 중심으로 대칭을 이룰 것이다. 그리고 필자는 이 모든 데이터를 다 검사할 수 없으니 1000여개 정도의 표본만 추출하여 전체 집단에 대해 분석을 추론한다고 해보자.
100만개의 데이터 중 1000여 개의 무작위 표본을 추출할 때, 필자가 한 쪽으로 몰린 극단적인 데이터만 추출할 가능성이 얼마나 될까? 아마 로또를 3번 맞고 벼락을 10번 맞을 확률보다도 더 낮을 것이다. 그리고 추출한 데이터의 분포와 평균은 전체 데이터의 분포/평균과도 크게 차이가 나지 않을 것이고 말이다. 그렇다면 대표값을 평균으로 잡고 분포도를 계산하는 것이 여러모로 편할 수 밖에 없다.
본격적인 설명을 위한 빌드업 과정이 상당히 길었는데, 이제 본격적으로 표준 편차를 왜 사용하는지에 대해 알아보자.
우리가 2차원 공간의 좌표 A점(1, 1)에서 B점(3, 3)으로 이동한다고 해보자. 이 두 점을 잇는 가장 짧은 경로는 직선이며, 이 직선의 길이는 { (3-1)^2 + (3-1)^2 }^1/2 = 2.82가 된다(자세한 내용은 피타고라스를 참고하자). 만약 직선이 아니라 격자를 따라가는 형태라면 가장 짧은 거리는 (3 - 1) + (3 - 1) = 4가 된다.
다시 데이터로 돌아와보자.
평균절대편차의 경우 공식의 폼을 보면, 격자를 통해 두 지점의 거리를 측정하는 방식과 비슷하다. 하지만 표준 편차는 제곱값 합에 제곱근을 적용하는 모습이 마치 피타고라스 정리식과 매우 유사하다.

이제 마지막 질문. 평균절대편차와 표준 편차 중 데이터 중 평균으로부터 데이터가 떨어져 있는 정도를 가장 잘 표현하는 것은 무엇일까? 위의 내용이 표준 편차를 사용하는 이유다.
DataFrame의 var(), std() 매서드는 이러한 배경을 가지고 있으며, 데이터가 무수히 많고 정규 분포(고른 분포)를 띈다고 여겨지는 데이터에 대해 분포 정도를 확인할 때 사용된다고 생각하면 된다.
7. 특정 필드 내 데이터의 쏠림 현상 확인하기: pandas.DataFrame["Column명"].skew()
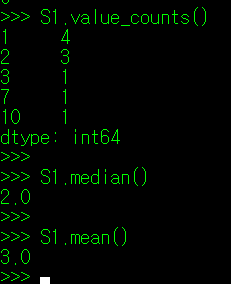
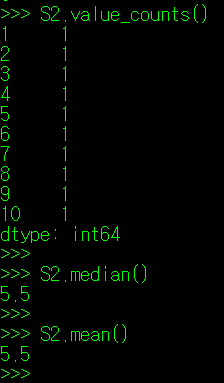
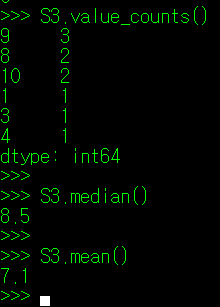
그럼, 분석할 데이터가 한 쪽으로 몰려있는지 아닌지는 어떻게 판단해야 할까? skew() 매서드를 사용하면 해당 정보를 알 수 있다(skewness는 조선말로 왜도라고 한다). 아래의 데이터를 보자. 필자가 3개의 데이터 조합을 만들었는데, S1은 평균에서 좌측으로 몰빵된 데이터, S2는 균등한 데이터, S3는 평균에서 우측으로 몰빵된 데이터이다. 이들 데이터에 대해 각각 skew() 매서드를 적용해보았다.
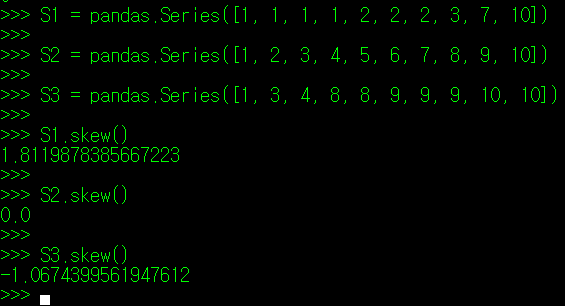
종 모양의 분포를 띄는 S2데이터 집합과 달리, S1은 종의 머리가 좌측으로, S3는 우측으로 치우친 형태를 보인다. 그리고 S1.skew()의 값은 양수를, S3.skew()의 값은 음수를 띈다. 이를 토대로, 알 수 있는 내용은 다음과 같다.
---------------------------------------------------------------------------------------
** skew() 값이 양수인 경우: 평균보다 작은 값의 데이터가 많음.(꼬리가 양의 방향)
** skew() 값이 0인 경우 : 평균을 중심으로 데이터가 고르게 분포
** skew() 값이 음수인 경우: 평균보다 큰 값의 데이터가 많음.(꼬리가 음의 방향)
---------------------------------------------------------------------------------------
skew() 값에 따라 특이한 점이 하나 더 있는데, skew()가 양수인 경우 최빈값(mode) < 중앙값 < 평균의 형태를 띄며, skew()가 음수인 경우 평균 < 중앙값 < 최빈값(mode)의 형태를 띈다.
통계학에서 -0.5 ~ 0.5 사이의 skew()값을 가지는 데이터는 골고루 분포한다고 여겨지며, 절대값 0.5 ~ 1 사이는 약간 치우친 정도로 여겨진다. skew()를 구하는 공식은 아래와 같다.
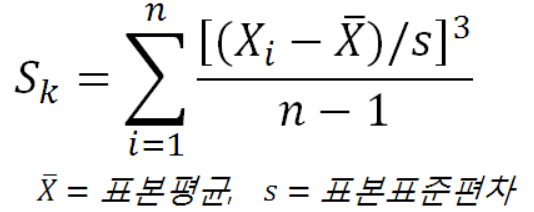
7. 특정 필드 내 데이터의 집중도(정밀도) 확인하기: pandas.DataFrame["Column명"].kurtosis()
다음으로 kurtosis() 매서드에 대해 알아보자. kurtosis는 조선말로 번역하면 첨도라고 하는데, 교회의 첨탑과 같은 단어에서 연상할 수 있듯이, 최빈값 주변으로 데이터가 얼마나 많이 분포했는지를 확인할 수 있는 값이다. 조금 더 정확하게 말하자면, 데이터의 분포가 정규분포에서 얼마나 벗어났는지를 보여주는 값이라 보면 된다.
아래의 데이터를 보자.

첨도(kurtosis)값이 높으면 높을수록 최빈값 데이터 수가 많아지는 것을 확인할 수 있다. 반대로 첨도가 낮을수록 최빈값에서 벗어나는 값이 많아진다. 첨도의 공식은 아래와 같다.
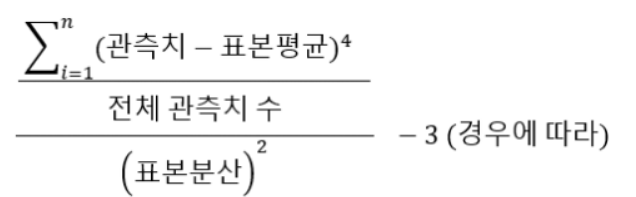
첨도가 3인 경우 데이터가 정규분포 형태를 따르며, 3 이상인 경우 데이터가 뾰족해지면서 이상치가 존재한다고 본다. 반면 첨도가 3 아래인 경우는 데이터의 이상치 범위가 상당히 완화되며 완만한 구릉 형태의 그래프를 나타낸다. Python pandas에서는 kurtosis() 매서의 결과값이 -3이 적용되지 않은 값으로 출력된다는 점을 주의하도록 하자.
첨도에 대해서는 추후 이상치와 관련된 내용을 다룰 때 한 번 더 언급하지 않을까 싶다.
8. 특정 필드 내 데이터의 중복 여부 확인하기: pandas.DataFrame["Column명"].duplicated()
마지막으로 특정 필드에 정의된 값 중 중복되는 내용이 있는지를 표시하는 duplicated() 매서드를 알아보자. duplicated() 매서드는 필드값이 이전 행에 존재하는지 여부를 표시하는 매서드다. 따라서, 행의 초반부에는 필드값에 duplicated()를 적용하면 대부분 False로 나타난다. 물론 상황에 따라 뒷 부분에 False가 나타나는 값도 있을 수 있다.
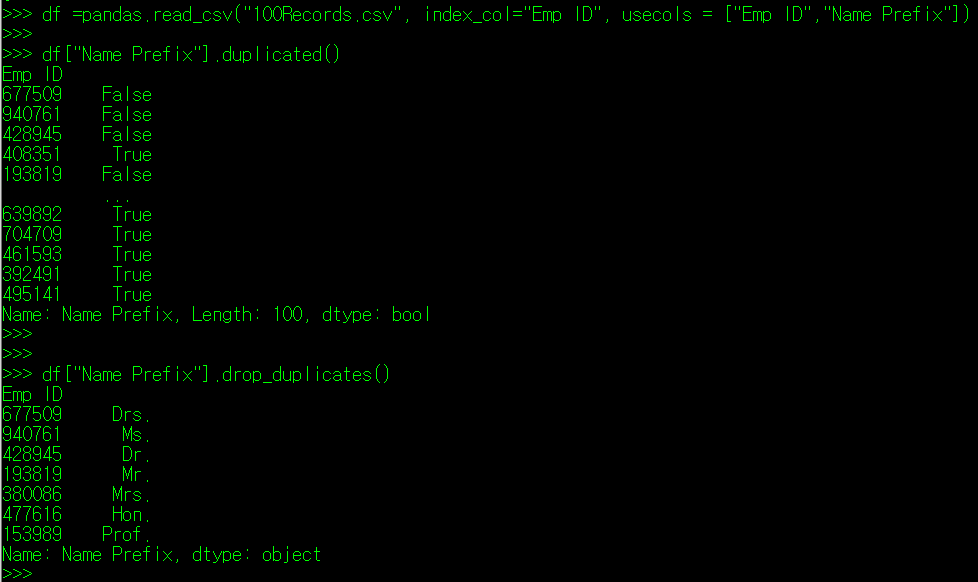
위의 내용을 보자. drop_duplicates()라는 매서드는 중복되는 값을 제외, 즉 duplicated() 매서드 결과가 False로 나타나는 행만 표시한다. duplicated가 True인 4번째 행의 내용은 drop_duplicates() 결과에 나타나지 않는 것을 확인할 수 있다. 보통 drop_duplicates()는 필드에 적용된 값의 종류를 찾는데 많이 사용한다.

Fin.
'Python > Python DataAnalysis' 카테고리의 다른 글
| [Python Data Analysis] 9. DataFrame 데이터 조건 검색 및 수정 (0) | 2021.11.20 |
|---|---|
| [Python Data Analysis] 8. DataFrame 데이터 슬라이싱 (0) | 2021.11.17 |
| [Python Data Analysis] 6. DataFrame 파일 입출력 (0) | 2021.11.08 |
| [Python Data Analysis] 5. DataFrame, Index 관련 매서드 (0) | 2021.11.03 |
| [Python Data Analysis] 4. DataFrame 객체 (0) | 2021.11.02 |




댓글