원래, Stack과 Queue에 대한 내용으로 이번 포스팅을 작성하려다, 정렬과 관련된 내용을 한 번 포스팅하고 넘어가야 할 듯 해서 급히 지난 포스팅의 뒷 부분을 수정했다. 사실 Stack과 Queue야 선형 구조인 배열의 파생 개념이라 크게 어렵지 않기 때문에 지금 포스팅으로 다루지 않는다고 크게 문제가 될 것도 아니다.
정렬의 경우에는 조금 이야기가 다르다. 정렬의 경우에는 프로그래밍을 하다보면 다루어야하는 데이터 셋이 무조건 발생하기 때문에, 조금이라도 더 효율적인 프로그램을 만들려면 다량의 데이터를 어떠한 규칙을 적용해 효과적으로 정렬할 수 있을지 계속 고민할 수 밖에 없다.

선형 자료구조의 정렬 알고리즘은 버블 정렬, 선택 정렬, 삽입 정렬, 힙 정렬 등등등 무수히 많다. 그 중에서도 앞으로 몇 개의 포스팅에서는 버블 정렬과, 버블 정렬의 개선 방안 및 버블 정렬로부터 파생되는 쉐이커(Shaker, 또는 칵테일) 정렬에 대해 알아보려한다. 이번 포스팅에서는 버블 정렬의 개요만 진행해보려한다.
1. 버블 정렬
버블 정렬은 개념이 단순하다. 선형 자료 구조 내 서로 인접한 위치에 존재하는 두 값을 비교하여 단순히 자리를 바꾼다는 개념이며, 이를 전체 배열에 적용하여 데이터를 정렬한다. 말로는 어려우니 예시를 보자.
배열 하나에 아래와 같이 4개의 숫자가 무작위로 들어있다.
ARR = [50, 80, 60, 30]
이 배열을 오름차순으로 재정렬하려고 한다. 버블 정렬은 서로 인접한 두 수를 비교한 뒤 자리를 교체한다고 했다.
먼저 필자는 기준 위치를 Index 0으로 정했다. 그럼 index 0과 비교하는 값은 index 1이다. 두 값은 50과 80인데, 50이 더 크기 때문에 30과 50위 위치가 변경되지 않고 아래와 같이 유지된다.
ARR_1_1 = [50, 80, 60, 30]
다음으로 버블 비교를 진행할 기준 위치를 Index 1로 잡아보자. 그러면 인접한 Index 2와 비교가 일어날텐데, Index1의 값은 Index 2보다 크므로 자리 교체가 발생한다.
ARR_1_2 = [50, 60, 80, 30]
다음으로 기준 위치를 한 번 더 옮겨 Index 3으로 가보자. 그럼 배열의 마지막인 Index 4와 비교를 진행하게 된다.
ARR_1_3 = [50, 60, 30, 80]
이렇게 첫 번째 버블 정렬이 완료되었다. 첫 버블 정렬이 완료된 후의 상태를 보면, 배열 내 최대값인 80이 배열의 마지막에 위치하고 있는 것이 확인된다.
이 상태에서 다시 한 번 버블 정렬을 진행해보자. 필자가 타이핑이 귀찮아서 굳이 세세한 설명은 달지 않겠지만, 두 번 째 버블 정렬을 마무리하고나면 배열 내에서 두 번째로 큰 값인 60이 N-1번 째 Index에 위치하게 된다.
ARR_2_2 = [50, 30, 60, 80]
마지막은 Index 0과 Index1만 비교를 진행하면 되기 때문에 최종적으로
ARR_3_1 = [30, 50, 60, 80]
이라는 오름차순이 완료된 결과가 나타난다.
필자가 예시로 든 ARR 변수명 옆에 숫자를 써 두었는데, 첫 번 째 숫자는 버블정렬의 수행 횟수고, 두 번 째 숫자는 비교 횟수다. 즉, 배열 내 버블정렬은 배열을 N-1번 돌며 최대 N(N-1) / 2 번의 비교를 진행하게 된다. 위의 예시에서도 알 수 있듯이 버블 정렬은 3회, 비교는 총 6회 진행된 것을 확인할 수 있다. 즉, 버블 정렬은 시간 복잡도가 Big-O 표기로 N^2가 된다.
2. 코드 구현
이제 버블 정렬을 구현하는 코드를 작성해보려한다. 정렬의 경우, 검색과 달리 데이터를 추가하거나 삭제하거나 조회하는 기능들이 불필요하기 때문에 단순한 함수로도 구현이 가능하다. 뼈대는 아주 단순하게 나온다.
이제 구현을 해보자. 버블을 시작하는 위치는 좌측이나 우측이나 상관이 없다. 필자는 예시에서 보인대로 좌측부터 기준점을 잡아 진행해보려한다. 먼저 버블 정렬 1회 실행 및 비교 횟수를 연산하는 코드를 작성해보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# Bubble Sortation with Python
def bubble_sort(arr: list) -> list:
arr_len = len(arr)
compare_cnt = 0
for idx in range(arr_len - 1):
if arr[idx] > arr[idx + 1]:
arr[idx], arr[idx + 1] = arr[idx + 1], arr[idx]
compare_cnt += 1
print(*arr)
print(f" * 비교 횟수: {compare_cnt}")
print()
|
cs |
크게 어려운 코드는 아니다. 한 번 버블 비교를 진행할 때마다 결과를 출력하고, compare_cnt 값에 1을 추가하는 단순한 코드다. 결과는 아래와 같이 나타난다.
첫 버블 정렬에서 선형 자료 내 최대값인 92가 가장 우측에 위치한 것이 확인된다. 이제, 저 92라는 값을 제외한 나머지 원소들로 다시 버블 정렬을 진행하고, 최대값을 다시 제외한 원소들의 버블 정렬을 다시 진행해야한다. 즉, 동일한 내용에 대한 반복이 이루어져야한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
def bubble_sort(arr: list) -> list:
arr_len = len(arr)
compare_cnt = 0
# 비교하는 원소는 2개 이상이어야 하므로 외부 Loop 조건을 arr_len >=2 로 설정
while arr_len >= 2:
for idx in range(arr_len - 1):
if arr[idx] > arr[idx + 1]:
arr[idx], arr[idx + 1] = arr[idx + 1], arr[idx]
compare_cnt += 1
print(*arr)
print(f" * 비교 횟수: {compare_cnt}")
print()
# 버블 정렬 후 최대값 제외를 위한 arr_len 값 감소
arr_len -=1
print("--END--")
|
cs |
위 코드의 결과는 아래와 같이 나타난다.
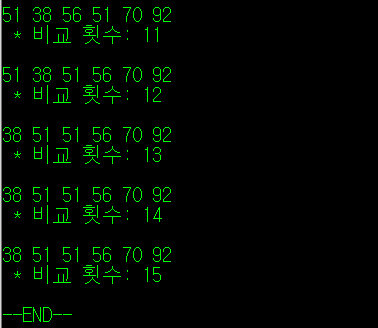
버블 정렬을 통해 중구난방이었던 숫자 데이터가 오름차순으로 최종적으로 정렬된 것이 확인된다. 수행 횟수 역시, 배열의 원소 수인 6을 서두에 설명한 수행횟수 공식에 넣었을 때 도출되는 값인 15와 동일히다. 주석 등 불필요한 내용을 제외하면 최종적으로 아래와 같은 형태의 코드가 나타나게 된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# Bubble Sortation with Python: Loop를 for나 while로 돌리는 것은 각자 취향껏 하자.
def bubble_sort(arr: list, reverse=False) -> list:
arr_len = len(arr)
while arr_len >= 2:
for idx in range(arr_len - 1):
if arr[idx] > arr[idx + 1]:
arr[idx], arr[idx + 1] = arr[idx + 1], arr[idx]
arr_len -=1
return arr if not reverse else arr[-1::-1] |
cs |
재귀 함수 형식으로는 아래와 같이 작성할 수 있다. 확실히 Loop 가 줄어드니 코드가 보기 좋아진다만, 필자의 PC에서 배열 크기가 996을 초과하니 메모리 문제인지 코드가 실행이 안된다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# Bubble Sorting with Recursive
# bubble_recursive: 버블 정렬 재귀함수
def bubble_recursive(arr: list, arr_len: int):
if arr_len == 2:
return arr
for idx in range(arr_len - 1):
if arr[idx] > arr[idx + 1]:
arr[idx], arr[idx + 1] = arr[idx + 1], arr[idx]
return bubble_recursive(arr, arr_len - 1)
def bubble_sort(arr: list, reverse=False) -> list:
arr_len = len(arr)
result: list = bubble_recursive(arr, arr_len)
return result if not reverse else result[-1::-1]
|
cs |
그런데, 위의 결과를 보면 버블 정렬은 불필요한 수행이 진행되는 경우가 있음을 확인할 수 있다. 마지막 CMD 스크린 샷을 보면, 굳이 버블 정렬을 최대 횟수인 15회를 돌리지 않더라도 13회에서 이미 정렬이 완료된 것이 확인된다. 그럼, 지금과 같이 정렬 도중에 모든 원소가 정렬이 최종적으로 완료되었을 때, 불필요한 수행을 하지 않을 방법은 없을까?
다음 포스팅에서는 버블 정렬의 개선 코드와 버블 정렬의 수행 횟수를 획기적으로 줄여주는 쉐이커(Shaker) 정렬에 대해 알아보려 한다.
END.
'Python > Python Data Structure and Algorithm' 카테고리의 다른 글
| [자료구조 with Python] 10 - 정렬 알고리즘(3), 삽입 정렬(Insertion Sort) (0) | 2024.03.11 |
|---|---|
| [자료구조 with Python] 9. 정렬 알고리즘(2) - 버블 정렬과 Shaker 정렬 (0) | 2024.03.08 |
| [자료구조 with Python] 7. 선형 자료 구조 - 배열(6), Hash 충돌과 개방 주소법(Open Address) (0) | 2024.03.05 |
| [자료구조 with Python] 6. 선형 자료 구조 - 배열(5), Hash 충돌과 Chaining (0) | 2021.01.23 |
| [자료구조 with Python] 5. 선형 자료 구조 - 배열(4), Hash검색 (0) | 2021.01.10 |




댓글