이번 포스팅은, 앞서서 보았던 DataFrame 데이터에 대해 특정 조건을 만족하는 값을 지니는 데이터 행을 추출하고, 기존에 존재하는 데이터를 바꾸는 방법에 대해 알아보려 한다. 특정 조건을 DataFrame에 명시하기 위해서, DataFrame의 특정 위치를 찾는 방법에 대해 어느정도 익숙한 상태여야 한다. 이 부분이 궁금하신 분들은 필자의 Python Data Analysis 이전 포스팅들을 참고하도록 하자.
오늘 확인할 내용은 아래와 같다.
[데이터 조건 검색]
# pandas.DataFrame[ 검색 조건1 & 검색 조건2] : 검색 조건1, 2를 모두 만족하는 데이터만 출력
# pandas.DataFrame[ 검색 조건1 | 검색 조건2] : 검색 조건1, 2 중 하나를 만족하는 데이터만 출력
# pandas.DataFrame.sort_values("Column명", ascending=False) : 특정 Column 값을 내림차순으로 정렬
# pandas.DataFrame.sort_values("Column명") : 특정 Column 값을 오름차순으로 정렬
[ 데이터 변경 ]
# pandas.DataFrame.loc[Index1, Column1] = "변경할 값" : 특정 위치의 값 변경
* iloc도 동일하게 적용할 수 있다. loc[]과 차이가 없어 별도로 언급하지는 않는다.
# pandas.DataFrame["새Column명"] = "변경할 값 리스트" : 변경할 값 리스트로 새 Column 추가
# pandas.DataFrame1.append(Tuple형식의 새 행 값 또는 새 DataFrame): DataFrame1 아래 행에 데이터 추가
# pandas.DataFrame1.join(pandas.DataFrame2) : DataFrame2를 DataFram1 우측에 열 추가
* append(), join() 유사 매서드: pandas.concat()
# pandas.DataFrame.drop(index ="Index명", column="Column명") : 특정 행, 열 삭제
# pandas.DataFrame["Column명"].replace(변경 전 Column 데이터 리스트,변경 후 Column 데이터 리스트)
:특정 컬럼의 값을 일괄 변경
# pandas.DataFrame.apply(함수명) : 특정 컬럼 값에 함수 적용
* 유사 매서드로 pandas.Series.map(함수명), pandas.DataFrame(Series).applymap(함수명)이 존재함.
I. 특정 조건을 만족하는 데이터 정보만 추출
1. 하나의 조건을 만족하는 데이터 추출
지금까지 사용해왔던 직원 정보가 포함된 CSV 파일을 사용하여 DataFrame을 만들어보자.

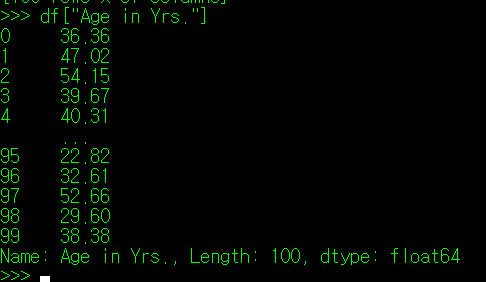
필자가 문득 이 자료를 보다가, 필자와 동일한 20~30대의 직원들의 정보가 궁금해졌다고 해보자. 이 데이터에서 나이는 "Age in Yrs."로 지정되어 있으며, 이 필드의 값이 20 이상 40 미만인 직원들만 추출하면 된다. 어떻게 하면 될까?
우선 나이와 관련된 Column만 추출해보자.

** 참고: 위에서 Column명이 제대로 뜨지 않는 이유는 출력된 결과가 DataFrame이 아닌 Series이기 때문이다. Series는 일차원 자료만 표시하는 pandas의 객체이며, DataFrame() 매서드를 통해 DataFrame으로 변화도 가능하다.

그럼, 이 중 20대와 30대는 어떻게 분류하면 될까? 다음과 같이 우리가 찾은 df["Age in Yrs."] 값 뒤에 조건을 달아보자.

앞서 배웠던 value_counts() 변수를 조건 뒤에 사용하면, 20대 이상(True)인 사람과 그렇지 않은(False) 사람의 수를 확인할 수 있다. 다행히 미성년자 불법 노동 착취는 없는 회사인지 20대 이하는 0명으로 나온다.

그럼, 40대 미만은 어떨까?

40대 미만은 57명으로 꽤나 젊은 회사다. 자, 그럼 이 57명의 자료만 별도로 추출하려면 어떻게 하면 될까?
앞선 포스팅에서 데이터 슬라이싱과 관련된 내용을 다룰 때, df[]에 대해 언급했었다. 이 df[]의 대괄호 안에는 index 또는 Column명이 들어가는 것이 일반적이지만, 위의 예시에서 사용한 조건도 입력하여 사용할 수 있다. 즉,

이런 방식으로 57명에 대한 자료만 추출할 수 있다. 현재 데이터 출력 결과에 나이가 나와있지 않으니 필자의 포스팅 신뢰성을 위해 조금 더 귀찮음을 감수해보겠다(그래봐야 얼마나 귀찮다고...)

2. 둘 이상의 조건을 만족하는 데이터 추출
이제 필자는 필자 나이대의 직원들이 필자보다 연봉을 많이 받는지 적게 받는지 알아보고. 많이 받는 사람의 인적 정보를 확인해(자객을 보내??)보려 한다.
우선 앞서 보았던 40대 미만에 대한 조건은 유지한 채, 연봉이 특정 금액 이상이 되는지 확인하는 조건을 만들어보자. 필자의 연봉은 60000 달라라고 가정하자.


위와 같이 두 개 이상의 조건에 부합하는 데이터를 찾기 위해서는 각 조건 사이 AND(&) 연산자를 사용하여 코드를 작성하면 된다. 일반 python의 조건문과 달리 and와 or가 사용되지 않는데, 그 이유는 and나 or를 마치 Series 객체 변수로 이해하기 때문이다.

만약 둘 중 하나의 조건(OR)만 만족하는 값을 찾으려면 & 대신 |(파이프)를 사용하면 된다. 굳이 이 내용까지는 스크린샷을 달지 않는다.
자, 필자가 자객을 보내야 하는 20~30대 직원이 너무 많다보니, 40대 이상 직원이면 그나마 수월하지 않을까 하여 조건을 다시 재검색해보려 한다. 이를 위해 condition 에 지정된 조건만 벗어난 상태로 condition2 조건과 AND로 엮이면 된다. condition 앞에 물결(~) 표시를 붙여 condition 조건을 부정한 뒤 검색해본다.

그나마 35명으로 줄긴 했는데... 그래도 너무 많다... 방법이 없을까?
3. Column값의 오름차순/내림차순 정렬
따라서 필자는 20대, 30대 직원 중 상위 5명의 정보를 먼저 확인해보기로 했다. 그러려면 처음 사용했던 조건을 연봉값에 따라 내림차순으로 정렬해야 한다. 오름차순, 내림차순 정렬에 사용하는 매서드는 sort_values()다.

실제 이들의 연봉 정보도 살펴보자.

이렇게 sort_value() 매서드를 사용하면 특정 Column값 순서대로 데이터를 정렬할 수 있다. sort_value()는 인자로 ascending(오름차순)을 가지고 있는데, 기본값은 True이기 때문에, ascending= False를 지정하지 않는 경우, 작은 값부터 순차적으로 데이터가 출력된다.
DataFrame이 아닌 Series 객체에서도 sort_values() 사용이 가능한데, Series 객체 특성 상, sort_values() 매서드를 Series와 사용할 경우 별도로 Column명을 명시하지 않아도 된다.

II. 데이터 정보의 수정
1. 데이터 행 추가: append()
위에서 사용한 DataFrame에는 필자의 데이터가 없다. 따라서 필자가 이 기업에 연봉 60000달러에 취직했다고 가정하고 데이터를 추가하려 한다. 우선 막 취직이 되어 전체 데이터를 넣지는 못하고, 이름만 넣는다고 해보자.
loc[]을 사용하면 다음과 같이 쓸 수 있다. 필자의 ID가 111111로 부여되었다고 가정하면
df.loc[111111] = ["Mr.", "Erwin", "H", "Wald", "M", "", "", ""......]
이렇게 DataFrame의 Column수에 맞게 List 값을 채워 넣어야 한다. 심지어 저 List 길이가 Column 숫자와 맞지 않으면 에러까지 발생한다.

빈 값이 있다면 이를 자동으로 넣어주면 좋을텐데 말이다. 이 때문에 나온 매서드가 append() 매서드다. append 매서드는 인자값으로 Dictionary를 이용하며, key 값으로 column 명을, value 값으로 column 값을 지정하면 된다.
시작하기에 앞서, 이전 DataFrame에 잡혀있던 index_col은 잠시 원상복구하도록 하겠다(뒤에서 설명할 예정이다)

다음으로 append() 매서드로 값을 넣어보자. 우선 이름과 성별만 집어넣기 위해, 아래와 같이 새 데이터 Dictionary를 제작한다. 그리고 append() 매서드 안에 제작한 Dictionary를 명시한다.

append(new_emp_dic) 결과 에러가 발생하는 것이 보인다. 에러 내용을 보니, Dictionary값으로 Append를 사용하면 반드시 ignore_index=True가 인자로 지정되어야 한다는 것이 보인다. 다시 에러의 권고에 따라 진행해본다.

다행히 이름과 성별이 마지막 행에 잘 들어가는 것이 보인다. 위에서 본 것과 같이 append()는 몇 가지 특이한 점이 있다.
- 명시되지 않은 Column 값에 대해서는 Not a Number(NaN)라는 값을 부여한다.
- Dictionary로 추가할 값을 지정할 경우 반드시 ignore_index 인자값을 True로 명시해야 한다.
그럼 여기서 궁금한 점이 하나 생긴다. "Dictionary 말고 다른 값을 Append 할 수 있다는 거네요?"
맞다. Dictionary 외에 DataFrame 타입이 이 append 내에 포함될 수 있다. 지금 만든 df에서 마지막에 추가한 것만 별도로 추출하여 df2라는 이름으로 저장하자.

이 상태에서 df.append(df2)를 쓰면 아래와 같이 새로 추가한 필자의 인적 정보가 포함되는 것을 알 수 있다.

append() 매서드로 DataFrame을 추가할 때, ignore_index 인자는 큰 문제가 되는데, index_col 내용이 추가할 내용이 없는 경우, 추가될 내용이 위치할 행의 정보가 index_col의 값으로 들어간다.

필자가 추가한 정보는 100번 째 행에 추가되는 내용이라 Emp ID값이 100으로 저장된다. df.index 값은 Tuple로 지정되어 변경이 불가하기 때문에, append 전에 모든 set_index를 reset 해주는 것이 마음이 편하다. 바꾸고자 하면 바꿀 수는 있는데 매우 번거롭다.

2. 특정 위치의 데이터 변경
그럼, loc[] 을 사용하여 필자의 연봉 정보를 작성해보자. 매우 간단하다.

loc이나 iloc으로 DataFrame 내 위치를 찾고, 값을 지정해주면 된다. 이러한 방식으로 다른 NaN 값에 대해서도 값을 변경해주면 된다. 하지만 나중을 위해 필자는 우선 NaN을 잠시 남겨두려 한다.
2. 새 컬럼 생성
그런데, 필자가 이 데이터를 가만보다보니, 이름이 굳이 저렇게 First, Middle, Last로 나뉘어져야 하는지 의문이 들었다. 따라서 Full Name이라는 이름의 Column명을 새로 만들고, 이름의 각 부분을 모두 합쳐주려 한다. 아래와 같이 df[]를 이용하여 새 Column을 생성하고 값을 지정해주자.


글씨가 작아서 잘 보이진 않는데, 마지막에 Full Name으로 Column이 추가된 것이 보인다. 필자는 이 자료를 기존의 CSV 파일에 to_csv() 매서드로 저장한다.
3. Index, Column의 삭제
이크... 필자가 입사하기도 전에 고연봉자들에게 자객을 보내려는 계획이 회사 인사팀 직원에게 발각이 되었다. 따라서 필자의 입사는 없던 것으로 하기로 하고 인사팀 직원이 필자의 인적 정보를 삭제하려고 한다. 그리고 필자가 생성한 Full Name Column 역시, 인사팀에서는 필요가 없는 정보라 지우려고 한다고 가정해보자.
DataFrame의 index와 column을 삭제하는 매서드는 drop()이다. drop의 경우, 인자로 index와 columns를 가지며, 삭제할 index와 column값을 이 인자에 명시해주면 된다.
먼저 필자의 데이터(행)를 삭제해보자.

drop() 매서드로 필자의 정보가 사라진 것이 보인다. 그런데, drop() 함수의 경우 함정이 하나 있다. drop()을 적용한 뒤, df로 인적 정보 데이터를 다시 불러보면 필자의 정보인 100번 Index는 사라지지 않음을 확인할 수 있다.

그럼, 삭제된 정보를 df에 적용하려면 어떻게 해야할까? df = df.drop()으로 적용해줄 수도 있지만, drop() 매서드 내의 인자 inplace를 쓰면 된다. inplace 인자는 변경 내용에 대해 기존 DataFrame에 적용할지의 여부를 결정하는 인자인데 기본값이 False로 되어 있다. 따라서 변경된 내용을 적용하기 위해서 inplace=True를 매서드 인자로 명시해주어야 한다.

다음으로 Column도 삭제해보자. Column의 삭제도 어렵지 않다.

만약 이 두 인자를 한 번에 지운다고 하면 index와 column 값에 대해 각각 명시해주면 되며, 복수의 Index나 Column 제거 시, 인자값을 리스트로 묶어 지정하면 된다. 아래와 같이.

4. 동일 Index, 상이한 Column을 가진 DataFrame의 병합: join()
필자의 고연봉자 자객 암살 시도로 인해 회사 인사팀에서는 이름과 연봉 정보를 분리하여 데이터를 관리하기로 했다. 따라서 다음과 같이 직원 ID와 이름 정보는 personal_info라는 변수로 인사팀에서 관리하고, 직원 ID와 연봉 정보는 Salary_info라는 변수명으로 경리팀에서 관리하기로 했다.

시간이 흘러, 새해가 되어 연봉협상을 할 때가 되었다. 회사의 CEO가 직원들의 연봉을 얼마나 줄 지 고민하기 위해 직원 정보를 가져오라고 인사팀에게 요청했다.
"어?? 그거 저번에 연봉정보는 분리했어요. 경리팀에서 관리중임."
"그래?? 경리팀! 연봉정보 데이터좀 줘요"
"네, 근데 저희 연봉 정보에 직원 ID 밖에 없어요. 이름이 누군지 모름."
"자료 두개를 번갈아가면서 체크해야 되는거야??"
CEO가 pandas를 배웠다면 이 문제는 단번에 해결할 수 있다. DataFrame은 join()이라는 매서드를 제공하는데, 이 매서드는 DB에서 Primary Key라고 불리는 값만 공유하고 있다면, 서로 다른 Column 정보를 가지는 데이터라도 하나의 표로 묶어주는 역할을 한다. 위의 예시로 설명하자면, 각 데이터는 Emp ID라는 공통의 Index Column(Primary Key)을 가지며, 데이터 Column명은 모두 다르기에 하나로 합쳐 줄 수 있다는 말이다. join() 매서드로 이 두 자료를 합쳐보자.

어?? 그런데 에러가 발생한다. 이 문제는 에러의 내용을 보면 알 수 있는데, 두 자료 모두 Emp ID라는 Primary Key를 가지고 있기 때문에 두 자료를 합치기 위해 이들의 이름을 구분할 수 있도록 suffix(접미사)를 지정하라는 말이다.
join()의 경우 인자에 lsuffix, rsuffix를 가지는데, 이 인자는 합치려는 두 DataFrame이 동일한 Column 명을 가지는 경우 이들의 Column 명 뒤에 구분자를 넣어준다. 즉, 필자가 lsuffix = "_personal", rsuffix = "_salary" 라고 인자를 지정하면 표는 다음과 같이 Emp ID_personla, Emp ID_salary가 포함된 병합 표가 나타난다.

그런데... 동일한 Column 값을 두 번이나 화면에 표시하는 것은 너무 비효율적이다. 보기도 어렵고 말이다. 하나로 합치는 방법이 있는데, 이를 사용하기 위해서는 두 DataFrame의 index_col을 모두 Emp ID로 지정해주어야 한다.

join() 매서드 인자 내에 합치고자 하는 DataFrame만 set_index 설정을 하고, on 인자를 사용해 병합하는 방법도 있다.

단, 이 방법은 Primary Key에 해당하는 Emp ID가 Index_col로 지정되지 않은 DataFrame 결과가 나타난다는 차이점이 있다.
** 유사한 기능을 하는 매서드로 pandas.concat도 있다. 이 매서드 인자는 서로 다른 DataFrame 변수를 LIst로 묶은 값을 사용하며, 행 또는 열로 병합할 수 있는 기능을 제공한다.

concat() 사용 시 주의할 점이 있는데, 매서드 인자 중 하나인 axis = 1 값을 지정하지 않는 경우, 기본값 axis = 0 이 적용되어 행으로만 값이 추가된다. 위의 예시도 보면 axis 인자의 미지정으로 인해 salary_info 데이터가 아래쪽 행에 추가된 것을 확인할 수 있다. 열에 추가하려면 아래와 같이 진행하면 된다.

5. Column 데이터를 다른 변수로 바꿔보자.
잠깐 회사의 막장 이야기는 뒤로하고, 통계학 관련 이야기를 하려 한다. 통계학에서도 각각의 데이터를 분류하기 위한 기준이 있다. 예를 들어 성별의 경우 남/녀로 나뉘고, 학업 성적은 A+/A/B+/B 등으로 나뉘는 등이 그 예시다. 이들도 성격에 따라 불리는 이름이 전부 다른데, 보통 아래와 같이 구분된다.
* 여기서의 변수는 Python 코딩에서 사용하는 변수와 관련이 없으며, 통계학에서 변수 대신 척도라고 하기도 한다.
(1) 자료 특성에 따른 데이터(변수) 분류
- 이산형 변수(Descrete Variable): 비연속적인 값으로 구분된 변수
* 명목 변수(Nominal Variable): 변수가 카테고리화되지만 값 사이 서열은 없는 변수. 단순 구분에 사용되는 변수.
(ex: 성별, 선수 등번호, 혈액형, 직원 ID 등)
* 서열 변수(Ordinal Varibale): 변수가 카테고리화되며, 값 사이 서열을 띄는 변수.
(ex: 대학 시험 성적(A+, A0등), 상/중/하, 학력(초졸/중졸/대졸), 직급(부장/차장/과장/대리/사원) 등)
- 연속형 변수(Continuous Variable): 연속적인 값으로 구분되는 변수
* 등간 변수(Interver Variable): 측정 변수 사이 간격을 가지며 단위가 부여되나, 절대 0점/비율의 의미가 없는 변수
(ex: 섭씨/화씨 온도, 별점, 통증의 정도(1~10), IQ 및 심리검사 점수 등)
* 비율 변수(ratio Variable): 측정 변수 사이 간격, 단위가 부여됨과 동시에, 절대 0점/비율의 의미를 가지는 변수
(ex: 거리, 길이, 매출액, 무게, 속도, 나이, 시간 등)
(2) 수량적 특성에 따른 데이터(변수) 분류
- 질적 변수(Qualitive Variable) : 비서열질적변수와 서열변수로 나뉨.
- 양적 변수(Quantitive Variable): 연속형 변수와 이산형 변수로 나뉨.
통계학 비전공자인 필자가 보기에 뭔가 중첩되는 내용도 있긴 한데, 통계학에서의 변수는 대략 위와 같이 분류하는 듯 하다. 다시 회사로 돌아와보자.
어떤 이유에서인지 CEO가 회사 내 남녀 직원의 임금 차이를 확인하고 싶다고 해보자. 그리고 이 자료는 외부로 유출되면 안된다는 지시를 내린다. 그렇다면 DataFrame의 Gender Column값의 M과 F를 모두 외부인은 알아볼 수 없는 값으로 변환해야 한다. 예를 들면 남성을 10, 여성을 20으로 말이다(일종의 명목 변수로 변경하는 것이지만 외부인이 알아볼 수 없는 값이라는 점에서 차이가 있겠다).
이 때 사용하는 매서드로 replace()가 있다. 이 Replace는 인자로 두 개의 List 값을 사용한다. 전자의 List는 변경 전의 값, 후자의 List는 변경 후의 값으로 말이다. 인사팀 직원은 아래와 같이 자료를 변환할 것이다.

참고로 replace() 매서드도 inplace=True를 적용해주어야 기존 DataFrame에 변경값이 적용된다.

6. Python 함수를 이용한 값의 연산 및 변환
이번에는 CEO가 직원 나이대별로 연봉을 얼마나 주고 있는지 알고 싶다고 하자. "Age in Yrs." Column 값을 보면 알겠지만, 모든 직원의 나이가 소숫점 단위까지 표기되고 있기 때문에 특정 범위로 구분된(비율) 변수로 변환되어야 한다. 즉, 20~29세는 20대로, 30~39는 30대로 말이다. 이는 앞서 보았던 명목변수 -> 명목변수 변환과는 차이가 있는데, 단순히 값을 바꾸는 것이 문제가 아니라 바뀐값을 적용하기 전에 연산이 진행되어야 하기 때문이다.
이렇게 연산과 관련된 내용으로 데이터 값을 변환시키는 것은 replace() 매서드를 사용할 수 없다. 대신 실무진은 나이를 나이대로 변환하는 Python 함수를 하나 생성하고, 그 함수가 "Age in Yrs." 컬럼에 적용되도록 하면 된다. 이 때 사용하는 매서드가 map()과 apply()가 있다.
먼저 함수부터 만들어주자. 함수명은 age_to_generation으로.

이제 "Age in Yrs." 컬럼의 내용에 이 함수를 적용해보자. df["Age in Yrs."]는 일차원 데이터이므로 type이 Series 이다. Series의 경우 함수 적용 시 map()이라는 매서드를 사용한다. 물론 apply() 매서드도 axis 인자값을 기본값(0)으로 사용하면 적용 가능하다.

map() 함수는 Series에 대해 사용하는 함수 적용 매서드이긴 하지만, DataFrame의 Column 값 Series에만 반응할 뿐 Index에는 반응하지 않는 듯 하다.
다음으로 apply() 함수를 적용해보자. apply()는 map()과 달리 DataFrame 객체에 포함된 매서드다. 따라서 DataFrame에 apply(Function_Name) 적용 시, 모든 Column에 적용된다. 하지만 인적 정보를 포함하는 우리의 예시 DataFrame은 모든 데이터가 정수형이 아니기 때문에 전체 Column에 대해 연산이 불가하여 아래와 같은 에러를 만든다.

다행히 apply()는 DataFrame 뿐만 아니라 Series 객체에도 적용이 가능하다. 따라서 아래와 같이 사용하는 것도 가능하다.

apply에서도 map과 동일하게 Series에서 가능한 이유는 lambda 식을 적용해보면 알 수 있다. 이는 조금 뒤에서 알아보자.
함수 적용에 사용되는 매서드는 applymap()도 존재한다. 특이하게도 applymap()은 단지 DataFrame 객체에만 적용된다.
따라서 데이터 타입이 연산이 필요한 숫자로 구성된 경우 많이 사용된다. 이제 회사를 떠나 두 사람이 다트를 하는 현장으로 가보자.
여기 A, B 두 사람이 다트 시합을 하고 있다. 서로 6개의 다트를 던져 각각의 점수에 제곱근을 취해 합한 점수가 높은 사람이 이기는 게임이다. 그리고 이긴 사람이 진 사람의 딱빰을 1점에 한 대씩 때리는 것으로 규칙을 정했다.
결과는 아래와 같이 나왔다.

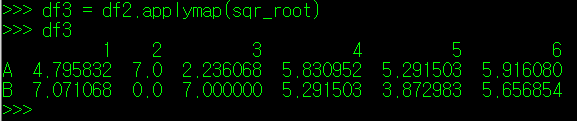
두 사람 각 다트 점수를 구하기 위해 모든 점수에 제곱근을 취해주어야 한다. 제곱근을 취하는 함수를 작성하고 applymap()으로 해당 함수를 적용하면 아래와 같은 결과가 나타난다.

이 값을 별도의 DataFrame 변수에 적용하고 결과를 살펴보자.
이제 각 점수의 총합을 구하여 딱밤 맞을 사람만 결정하면 된다. 계산해보면 A가 B에게 딱밤 2대만 때리면 되는 것을 알 수 있다.

이제 앞서 적용한 세 가지의 함수 적용 매서드의 차이에 대해 정리해보자.
우선 map()과 applymap()은 개별 값에 대한 데이터에 대한 연산을 진행한다. lambda 식으로 map(), applymap()에 적용되는 값을 출력해보면 다음과 같이 개별 데이터가 나타남을 알 수 있다.


반면, apply의 경우, DataFrame 객체에 lambda 식을 적용하면 개별 데이터가 아니라 행, 열의 Series 데이터 묶음이 적용됨을 알 수 있다.

따라서 apply() 매서드를 사용하면 특정 행과 열의 데이터를 사용하여 최소값, 최대값을 결과로 저장하거나 지금처럼 점수의 합산값을 출력하는 것도 가능하다.

apply의 경우 axis 인자값에 따라 행값을 연산할지, 열값을 연산할지 결정하는데, 기본값(0)인 경우 열 값에 대한 연산을, axis = 1인 경우 행 값에 대한 연산을 진행한다.
Fin.
'Python > Python DataAnalysis' 카테고리의 다른 글
| [Python Data Analysis] 11. 데이터 분석 절차 (0) | 2021.12.12 |
|---|---|
| [Python Data Analysis] 10. DataFrame 이상치/결측치 데이터 전처리 (0) | 2021.11.22 |
| [Python Data Analysis] 8. DataFrame 데이터 슬라이싱 (0) | 2021.11.17 |
| [Python Data Analysis] 7. DataFrame 데이터 정보 확인 및 기본 통계 (0) | 2021.11.14 |
| [Python Data Analysis] 6. DataFrame 파일 입출력 (0) | 2021.11.08 |




댓글