이번 포스팅에서는 pandas의 DataFrame 데이터를 전처리하는 방법에 대해 알아보려 한다.
데이터의 전처리는 앞선 포스팅에서 설명했다시피 scikit-learn 이라는 패키지를 사용한다. 따라서 본 포스팅을 참고하기 전, pip 명령어(python 3버전은 pip3 명령어)를 통해 아래와 같이 scikit learn 패키지가 설치되어 있는지 확인하도록 하자. numpy와 scipy도 데이터 분석에서 많이 사용하는 패키지이므로 같이 설치해주도록 하자. pip 명령어로 패키지를 설치하는 방법은 여기를 참고하자.

설치가 완료되었다면 python 실행 후, import sklearn을 입력해보자. 아무 애러 없이 프롬프트가 떨어진다면 Scikit Learn이 제대로 설치된 상태다.
데이터는 이전 포스팅에서도 사용했던 기업 내 직원의 정보가 기입된 데이터를 사용하려 한다.
1. 특성치 데이터의 정규화
불러들인 Data의 크기 및 columne들을 살펴보자.
** pandas의 기본적인 사용 내용은 이곳을 참고하자.
필자는 이 데이터들로부터, 각 직원의 연봉에 영향을 미치는 인자가 무엇인지 알아보고 싶다. 가령, 비만일수록 연봉이 낮아질지 아니면 반대로 높아질지, 혹은 근속연수가 오래된 직원일수록 연봉이 낮아질지 높아질지 등을 말이다. 먼저 37개의 컬럼 중, 필자는 근속연수가 연봉에 유의미한 영향을 주는지 확인해보려 한다. 따라서 다음과 같이 기존 DataFrame의 일부를 추출하여 새 DataFrame을 생성했다.
새 DataFrame에서 필자가 특성치 X로 사용할 자료는 "근속 년수"다. 따라서 아래와 같이 특성치 X와 레이블 Y를 분류한다.
이제 별도로 추출한 "근속연수" 데이터를, 분석하기 좋게 정규화하는 과정을 거쳐야 한다(정규화가 필요한 이유는 이곳에서 확인하자). 정규화를 위해서, 서두에 언급한 scikit learn 패키지 중 preprocessing(전처리) 클래스를 Import 한 뒤, 아래와 같이 하위 클래스들을 살펴보자.
preprocessing 클래스에는 정규화와 관련된 여러 하위 클래스를 제공하고 있는데, 이 중 MinMaxScaler(최대최소척도)와 StandardScaler(표준정규화)를 많이 사용한다. 이들 정규화 클래스의 사용을 위해 보통 아래와 같은 방식으로 Import를 많이 한다.
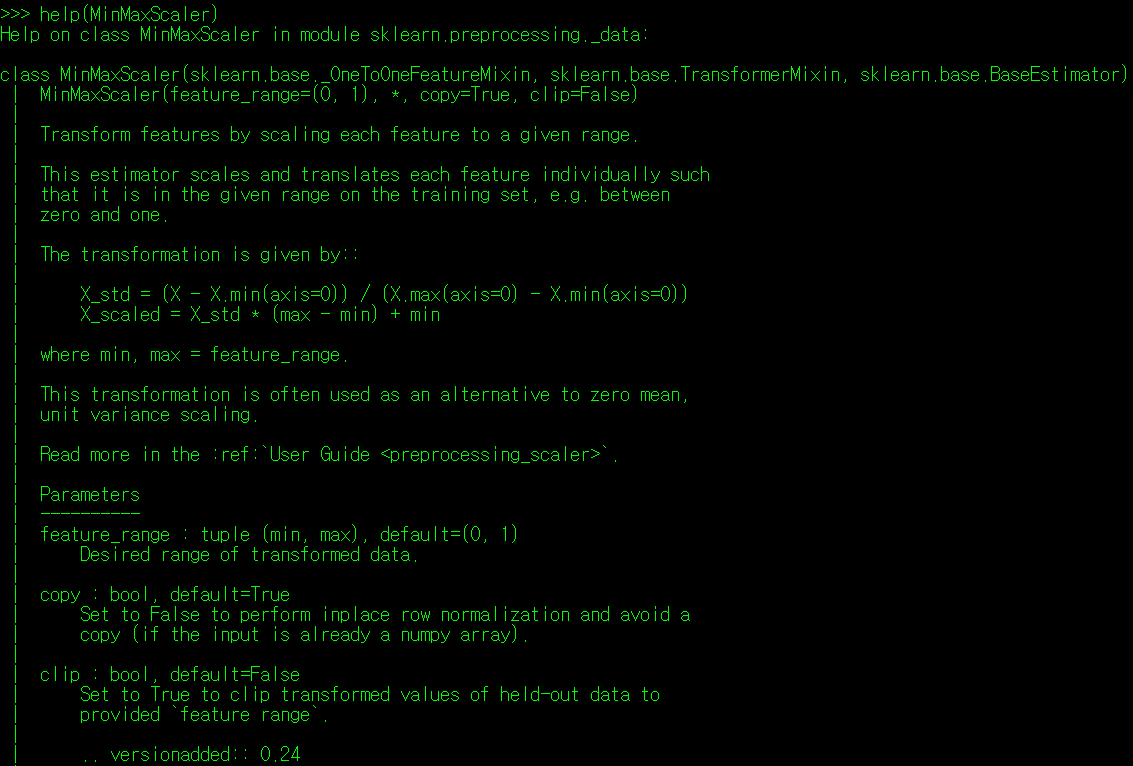
각 정규화 클래스에 대한 Import 가 완료되었다면, help 함수로 각 정규화 클래스에 대한 설명을 확인할 수 있다.
이제 특성치 X를 정규화 클래스를 이용하여 값을 분석하기 좋게 변환해보자.
(1) 각 정규화 클래스의 변수 선언 없이 변환하는 방법
각 정규화 클래스는 fit()와 transform() 이라는 이름의 하위 메서드(함수)를 공통으로 가진다.
fit() 매서드는 특성치 X 값을 각각의 정규화 방식에 맞게 변환하기 전 특성치의 최대/최소값 등을 확인하여 변환할 수 있도록 학습하는 기능을 하며, transform() 매서드는 fit() 매서드로 학습된 변환 방식에 따라 특성치의 다른 값을 정규화 값으로 변환하는 기능을 가진다.
먼저 MinMaxScaler, 최소최대척도부터 보자.
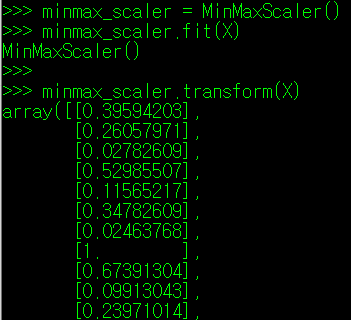
MinMaxScaler 클래스의 fit 매서드를 사용하여 특성치 X를 MinMaxScaler로 변환하기 위한 학습을 진행해보자.

MinMaxScaler는 클래스 형태를 띄기 때문에 사용 시 변수명 뒤에 괄호()를 붙여주어야 하위 매서드 사용이 가능하다. fit() 매서드는 인자로 DataFrame 형태의 특성치 데이터를 가지며, 인자 형태가 DataFrame으로 제대로 인식된다면, 위와 같이 MinMaxScaler() 라는 결과가 화면에 출력된다. 이 화면이 출력되면 특성치 X를 최소최대척도로 변환하기 위한 학습이 완료된 상태다.
이제 특성치 X를 최소최대척도로 변환한 뒤, X_minmax라는 값에 저장해보자. 변환 학습 내용을 적용하기 위해 transform() 매서드를 사용하며, 인자는 fit() 매서드와 마찬가지로 DataFrame 형태의 특성치 X를 지정해주면 된다. 단, transform() 매서드 사용 시, 어떤 학습과정을 거쳤는지 명시하기 위해, MinMaxScaler().fit(X) 코드 뒤에 transform() 매서드 코드를 작성해주어야 한다.
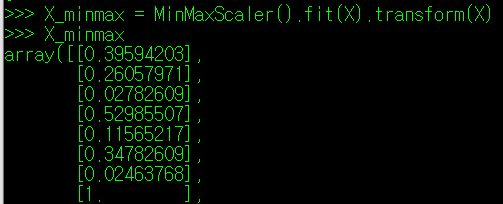
X_minmax 값은 DataFrame 형태가 아닌 Array 형태이기 때문에 추후 DataFrame 형태로 활용하려면, 아래와 같이 변수에 저장되는 값의 타입을 변경해주어야 한다.
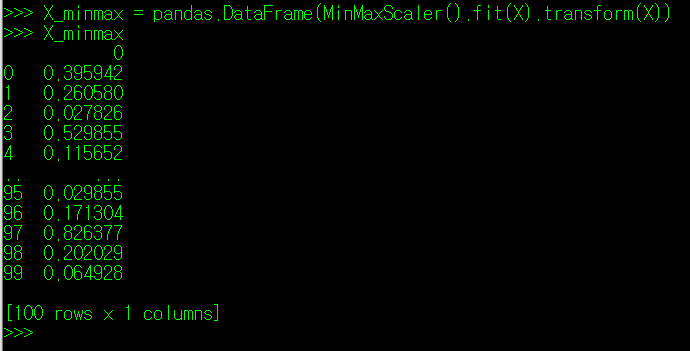
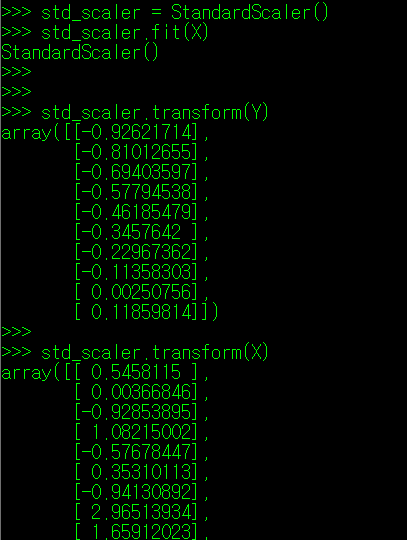
StandardScaler 방식의 경우에도 MinMaxScaler와 동일한 방식으로 특성치 X에 대한 정규화를 진행해주면 된다. 결과값은 아래와 같이 나타난다.

(2) 각 정규화 클래스의 변수 선언 후 변환
하지만 위의 방식으로 특성치를 변환하는 것은 불편한 점이 하나 있다. 만약 다른 특성치 데이터를 동일한 방식으로 변경하려면, fit()와 transform() 매서드를 항상 동시에 사용해야 한다는 것이다. 만약 fit() 매서드 없이 데이터 변환을 시도하면 아래와 같이 에러가 발생한다.
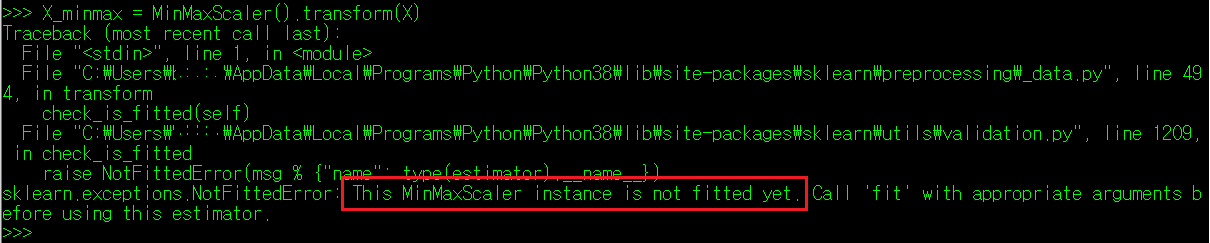
따라서, 일반적인 경우, 아래와 같이 각 클래스를 변수로 선언하고 fit() 매서드를 적용한 뒤, fit() 매서드가 적용된 클래스 변수에 곧바로 transform() 매서드를 사용하는 방식을 사용한다.
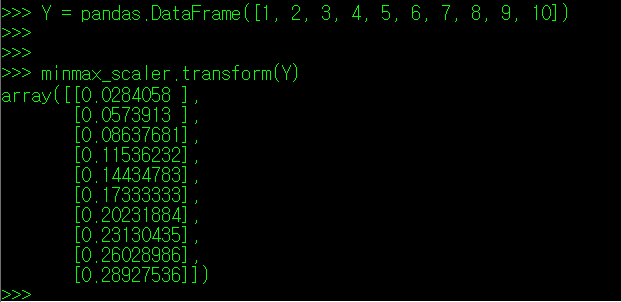
이 경우, 기존의 특성치 뿐만 아니라, 다른 특성치 값 역시 기존 학습 내용을 참고하여 변환하는 것이 가능해진다.
표준정규화도 동일한 방식으로 클래스 변수 선언 후 특성치 변환을 진행할 수 있다.
다음 포스팅에서는 특성치 X 데이터가 범주형인 경우, 정규화를 진행할 수 있도록 변환하는 One-Hot-Encoding 방식에 대해 알아보려 한다.
Fin.
'Python > Python DataAnalysis' 카테고리의 다른 글
| [Python Data Analysis] 14. pandas 데이터 전처리 - 학습/검증 데이터 특성치 분류 (0) | 2021.12.23 |
|---|---|
| [Python Data Analysis] 13. pandas 데이터 전처리 - One-Hot-Encoding (0) | 2021.12.23 |
| [Python Data Analysis] 11. 데이터 분석 절차 (0) | 2021.12.12 |
| [Python Data Analysis] 10. DataFrame 이상치/결측치 데이터 전처리 (0) | 2021.11.22 |
| [Python Data Analysis] 9. DataFrame 데이터 조건 검색 및 수정 (0) | 2021.11.20 |




댓글