이번 포스팅에서는 수집한 데이터에서 나타나는 이상치와 결측치를 다루는 방법에 대해 다루려 한다. 먼저 포스팅을 진행하기 전에 이상치와 결측치라는 용어의 의미를 알아볼 필요가 있다.
그 전에, 오늘 살펴볼 매서드에 대해 간략히 정리한다.
# pandas.DataFrame.isnull() : 결측치 여부를 True/False 값으로 반환. 결측치인 경우 True
# pandas.DataFrame.notnull() : 결측치 여부를 True/False값으로 반환. 실측치인 경우 True
# pandas.DataFrame.dropna(axis) : 결측치가 포함된 데이터를 제외하고 추출
(axis = 0 인 경우 결측치가 포함된 Index 삭제, 1인 경우 Column 삭제)
# pandas.DataFrame.fillna("대체값") : 결측치 데이터를 "대체값"으로 적용
* fillna() 매서드의 method 인자값을 ["ffill", "pad"] 중 하나로 지정하여, 결측치 앞의 값으로 대체할 수 있음.
* fillna() 매서드의 method 인자값을 ["bfill", "backfill"] 중 하나로 지정하여, 결측치 뒤의 값으로 대체할 수 있음.
# numpy.where("조건", "조건 True 시 대체값","조건 False 시 대체값")
: 새 Series 생성 시, 결측값의 여부에 따라 대체값을 다르게 지정
I. 이상치와 결측치
- 이상치(Outlier) : 수집 데이터 모음(데이터 셋이라고 한다) 값 중, 다른 데이터에 비해 매우 크거나 작은 값
- 결측치(Missing Value): 데이터 수집 과정에서 측정되지 않거나, 누락된 데이터.
이상치와 결측치는 데이터 분석 결과에 지대한 영향을 끼치기 때문에 데이터 분석 전 전처리과정(Preprocessing)에서 삭제 또는 변환 과정을 거쳐야 하는 데이터들이다. 그런데, 왜 그래야하는 것일까?
이상치부터 살펴보자. 대부분의 대한민국 봉급쟁이들(전체 근로 인구의 85%로 가정하자)이 받는 월급이 약 200~250만원 언저리라고 한다. 대기업 종사자들이 대략 350~400을 받고 이들이 전체 근로 인구의 약 8%~10%를 차지한다고 해보자. 이들 값으로 나올 수 있는 근로자의 월급 평균은 대략 200 중후반대에 자리잡힐 것이다. 데이터를 조금만 넣어보자.

9명의 근로자에 대한 평균 월급이 228만으로 나온다. 이제, 월 1000만원을 버는 유투버 1명의 월급 정보를 Series 안에 포함해보자.
한 순간에 평균 월급이 80만이나 뛰어버린다. 그렇다면, 유투버 1명의 극단적으로 많은 월급이 반영된 저 평균치는 나머지 9명 근로자의 연봉 데이터를 정확하게 반영한다고 볼 수 있을까? 당연히 그렇지 않다. 따라서 이런 극단적인 값을 제거/변환하여 데이터를 보정하는 작업을 진행해야 한다.
결측치 또한 마찬가지다. 사회 조사 연구를 통해 사람들에게 여러 정보를 설문지로 받는 과정에서 일부 대상자들이 질문 작성 시 문항을 한 두 개 빠뜨리고 제출할 수도 있다. 이 때는 값이 0이 아닌 측정되지 않은(Missing Value) 값으로 들어가기 때문에 평균을 내거나 총합을 구하는 연산을 진행할 수 없게 된다. 따라서 결측치가 발생한 데이터에 대해서도 보정 작업이 들어가야 한다.
결측치는 데이터가 누락된 값이기 때문에 연구자가 임의의 값을 넣어주면 된다. 이 방법은 뒤에서 살펴볼 것이다. 그런데, 이상치의 경우는 문제가 된다. 얼마나 극단적인 값을 이상치로 정해야 하는 것일까? 통계 연구자들마다도 이 이상치 기준이 없는 경우 자의에 의해 기준이 정해질 것이기 때문에 연구자마다 서로 다른 결과가 나타날 수도 있다. 다행히 통계학이라는 학문은 일상 생활에서 떼어놓고 지낼 수 없는 학문이라 이상치를 정하는 기준이 꽤 많이 정립되어 있다.
II. 이상치(Outlier)
1. 이상치 데이터의 기준
수집한 로우(Raw) 데이터 셋에서 이상치 데이터를 찾는 방법으로 Tukey Fences 방식이 있다.
Tukey Fences는 데이터 셋의 사분위 수를 바탕으로 이상치를 측정하는 방법이다. Tukey Fences를 이해하기 위해 아래의 IQR이라는 녀석에 대해 조금 알아볼 필요가 있다.
IQR(Inter Quantile Range). 조선말로 사분범위라고 불리는 개념인데, 이는 데이터 셋의 3사분위값과 1사분위값의 차이를 의미한다. 즉, 위에서 본 10명의 월급 데이터에 대해 IQR을 구하면 아래와 같이 나타난다.
** 사분위수를 구하는 코드는 여기를 참고하자.
Tukey Fences 방법에서는 이상치를 "1사분위 값 - IQR * 1.5"에 미달하거나, "3사분위 값 + IQR * 1.5"를 초과하는 값으로 정의한다.
Outlier = (df["column명"] < df["column명"].quantile(0.25) - IQR * 1.5) & (df["column명"] > df["column명"].quantile(0.75) + IQR * 1.5)
유투버 1명이 포함된 월급 데이터 셋에서 이상치를 제외한 자료를 sample_salary_tmp로 저장하고 이들의 평균을 구해보자. 아래와 같이 나온다.
위의 결과를 보면 알겠지만 측정 대상의 대다수를 대표할 수 있는 평균값으로 보정이 된 것을 알 수 있다.
2. 이상치의 처리
이상치를 처리하는 방식은 크게 아래의 4가지가 있다.
- 이상치의 삭제(Delete)
- 이상치의 값 대체(Replacement)
- 데이터 셋의 축소/과장(Scaling)
- 데이터 셋 최소최대척도(MinMax Scaling) 적용
- 데이터 셋의 정규화(Normalize)
(1) 이상치 삭제 (Delete)
이상치 삭제는 위의 예시에서도 보았듯이, 극단적으로 크거나 작은 값을 제거함으로써 분석 값을 조금 더 보정하는 방식이다. 앞선 예시에서도 유투버 1명과 대기업 직원 1명의 월급이 이상치로 빠지니 대다수 근로자의 임금과 유사한 평균값이 나타남을 알 수 있었다. 그럼, Tukey Fences 방식으로 나타난 이상치를 제거하는 것이 무조건 올바른 분석 방법일까? 그렇지는 않다. 당연하게도 이상치로 측정된 데이터라도 극단적인 값이라고 배제하고 분석할 수 없기 때문이다. 어찌되었든 극단적인 값도 분석 결과에는 포함되어야 한다.
그렇기 때문에 이상치를 보정하는데 이상치 삭제 대신 아래의 방식들을 많이 사용한다.
(2) 이상치 값 대체(Replacement)
이상치 값을 대체함으로써 데이터 셋을 보정하는 방법도 있다. 이상치를 대체하는 방법으로 아래의 내용을 보자.
- 하한값 / 상한값 결정 후, 하한값보다 작으면 하한값으로, 상한값보다 크면 상한값으로 대체
- 중위수로부터 n 편차 큰 값으로 대체
- 평균의 표준편차 * n 범위를 초과하는 값일 경우, 평균 +- (표준편차 * n) 값을 하한/상한값으로 지정.
....
그 외에 여러 대체 값이 있다.
하지만 이상치값을 다른 값으로 대체하는 방법도 잘 사용되는 방법은 아닌데, 실제 극값 정보를 분석 결과에 적용하기 어렵기 때문이다. 예를 들어 상한값을 초과하는 이상치만 10개 존재한다면, 이들 값을 상한값으로 대체함으로써 데이터 값 자체의 신뢰성이 떨어진다는 문제가 생긴다(12억 연봉 받는 사람의 데이터를 상한선인 6억 값으로 변경했다고 가정해보자. 과연 데이터의 분석 신뢰성이 올라갈까?)
(3) 데이터 셋 축소/과장(Scaling)
우리가 맨 처음 수집하는 데이터들은 보통 좌로 치우치거나 우로 치우친 값이 많다. 위의 예시로 보았던 연봉과 점수도 한 번 skew() 매서드를 사용해 살펴보자.
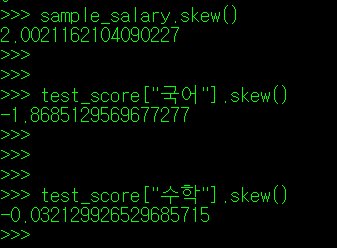
** skew() 관련된 내용은 여기를 참고하자.
연봉의 경우 좌로 치우친 그래프, 국어 점수는 우로 치우쳐진 그래프 형태다(우연하게도 수학은 정규분포 모양이다)
좌로 치우쳐진(Positive Skew, Right Skew) 데이터의 경우, 각 데이터 값을 축소해주면 skew 값이 0에 근접한다. 반대로 우로 치우져친(Negative Skew, Left Skew) 데이터는 각 데이터의 값을 뻥튀기해주면 skew 값이 0에 근접한다. 전자의 경우 제곱 또는 지수곱을, 후자는 로그나 제곱근을 사용하여 값을 보정한다.
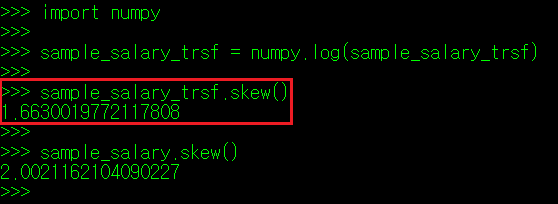

(4) 데이터 셋 최소최대척도(MinMax Scaling)
최소최대척도는 최대값을 1, 최소값을 0으로 변환한 뒤 각 구간값을 0~1 사이 스케일로 적용하는 방식이다.
국어 점수와 수학 점수에 대해 MinMax Scaling을 적용하는 식은 아래와 같다.
** MinMax_Scale = { (관측값 X) - (최소값 Min) } / { (최대값 Max) - (최소값 Min) }
국어 점수와 수학점수에 최소최대척도를 적용하면 아래와 같이 나타난다.
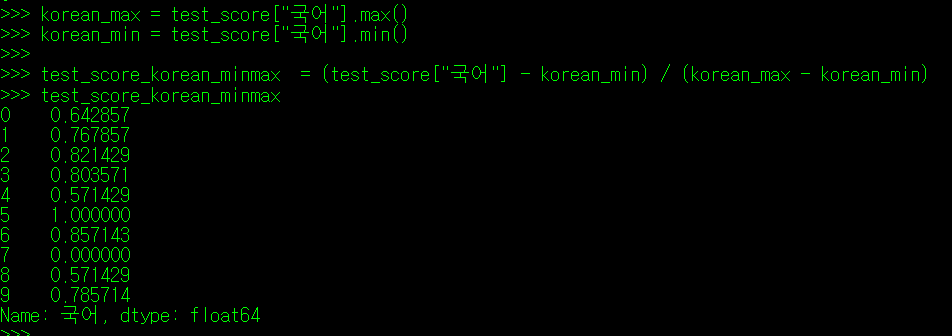
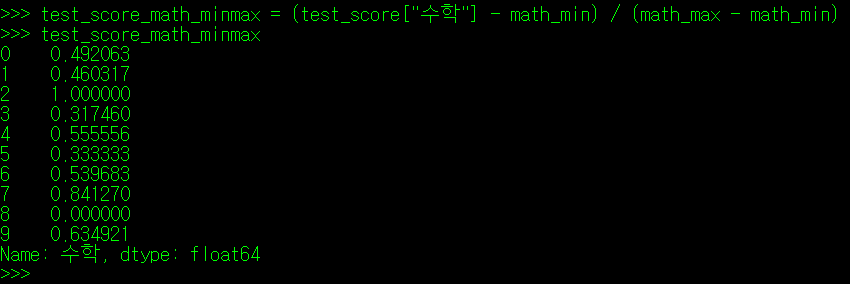
(5) 데이터 셋 정규화(Normalize) - Z값(Z-Score)
다음으로, 범위가 정해져 있는 값을 가지는 통계치에 대해 알아보자. 가장 좋은 예시는 학교 시험 성적이다. 0점부터 100점의 구간 내에서 10명의 학생이 받은 국어/수학 점수 분포가 아래와 같다고 해보자.
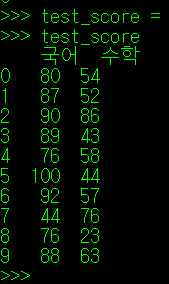

국어 시험이 조금 더 쉽게 출제되어 수학보다 평균이 무려 25점 가까이 높다. 이제 아래의 그래프를 보자.

이제 이 값들에 대해 Tukey Fences방식으로 이상치를 구해보자. 각 과목의 점수 이상치는 아래와 같이 나타난다.


여기서 필자가 이 시험에서 국어 86점, 수학 86점을 맞았다고 가정해보자. 그럼 필자는 100점 만점에 둘 다 86점을 맞았으니 평타를 친 성적이라 보아야 할까? 그렇지 않다. 두 시험간의 난이도가 다르기 때문에 수학 86점이 국어 86점에 비해 훨씬 좋은 성적이다. 그럼 국어 성적은 몇 점이 되어야 필자가 수학점수에서 받은 86점만큼의 값어치가 있는 것일까? 어림잡아보아도 최고점인 100점은 초과해야 할 듯 하다. 따라서 수학에서 86점이라는 점수가 이상치로 잡히더라도 국어에서는 이 점수가 이상치로 잡혀서는 안된다. 이 때문에 두 시험 성적 데이터를 표준화하는 작업이 진행되어야 한다.
위의 예시처럼 난이도와 같이 다른 요소에 의해 데이터가 보정되어야 하는 순간이 발생할 수 있다(TOEIC과 TEPS 점수도 비슷한 예시로 들 수 있다. 이들 사이 환산 점수에 대한 것도 말이다). 이들 데이터는 그래프 상에서의 보정된 점수 분포를 좌우 대칭으로 맞춤으로써 비교가 수월하게 만들어준다. 이 때 나타나는 그래프는 중앙을 대칭점으로 종 모양을 띄고 있어 종 모양 분포를 띈다고 말한다. 고등학교 수학 시간에 배웠던 정규 분포가 바로 이 녀석이다.
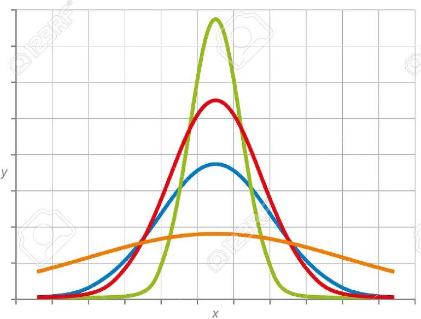
정규분포(Normal Distribution, Gausian Distribution) 그래프는 평균 값에 대해 대칭을 띄며, 표준 편차에 따라 그래프의 첨도가 달라진다. 그래프 곡선에 대한 공식(확률밀도함수라고 부른다)은 아래와 같다(μ = 평균, σ = 표준편차).
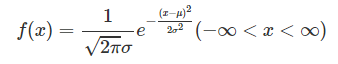
그런데 국어점수와 수학점수는 평균값과 표준편차가 다르기 때문에 이들에 대한 보정도 진행해주어야 한다. 즉, 정규 분포에 대해서도 표준화를 진행해주어야 하는데, 정규분포의 표준화가 진행된 결과를 표준정규분포라고 한다.
표준 정규분포(Standard Normal Distribution)은 평균이 0, 표준편차가 1인 정규분포 그래프이다. 위 정규분포식에 평균 0과 표준편차 1을 대입하면 아래와 같은 표준정규분포 식이 완성된다.
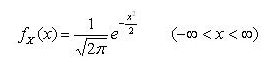
정규분포로 변환된 데이터라고 하더라도 이상치를 지정할 수는 있다. 그럼 정규분포로 변환된 데이터에서 이상치를 찾아보자. Tukey Fences 방식은 사용할 수 없는데, 우리가 데이터 셋을 바꿔 숫자가 많이 틀어졌기 때문이다. 그럼, 정규분포 데이터에서 이상치 기준은 어디로 정해져 있을까?
Tukey Fences가 1, 3사분위 지점에서 IQR의 1.5배 떨어진 거리의 범위를 벗어나는 값을 이상치로 지정했다. 정규분포에서도 IQR과 비슷한 역할을 하는 녀석이 있는데, 바로 Z-Score 라는 놈이다. Z-Score는 아래와 같이 정의한다.
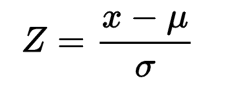
정규분포에서의 이상치는 저 Z값의 절대값이 3 이상이 나타나는 데이터를 이상치로 지정한다.
III. 결측치(Missing Value)
결측치는 이상치와 달리 삭제가 필요없다. 원래 없던 값이니까. 따라서 이상치와 달리 결측치 처리 시 변환 과정은 없으며 결측치의 삭제/대체 방법으로만 처리한다.
1. 결측치 처리
필자가 앞서 사용했던 직원 정보 DataFrame으로 넘어가보자. 이 원본 CSV 파일의 일부 데이터를 삭제하고 공란으로 만든 뒤, DataFrame으로 다시 호출했다.
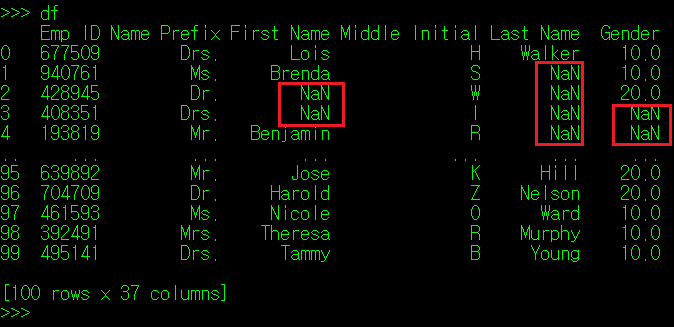
화면에 보면 공란으로 비워진 부분은 NaN으로 표시되는데 Not A Number의 준 말로 값이 없음을 의미한다. 이 NaN 값이 Column 값으로 포함되면 당연히 데이터 분석 결과의 신뢰도도 떨어질 수 밖에 없다. 따라서 결측치도 이상치와 마찬가지로 전처리 과정을 통해 데이터를 보정해주는 작업을 진행한다.
결측치의 처리는 아래의 두 가지 방법이 있다.
- 결측치 데이터 삭제(Delete)
- 결측치의 대체(Replacement)
(1) 결측치 데이터 삭제(Delete)
결측치 데이터 삭제는 말 그대로 결측치가 포함된 Index의 데이터를 삭제한다는 의미다. 먼저 각 데이터의 결측치 존재 여부를 살펴보자.
DataFrame의 매서드 중 isnull() 매서드가 존재하는데, 이 매서드는 DataFrame의 각 값 중 NaN인 데이터를 True로 반환하는 역할을 한다.
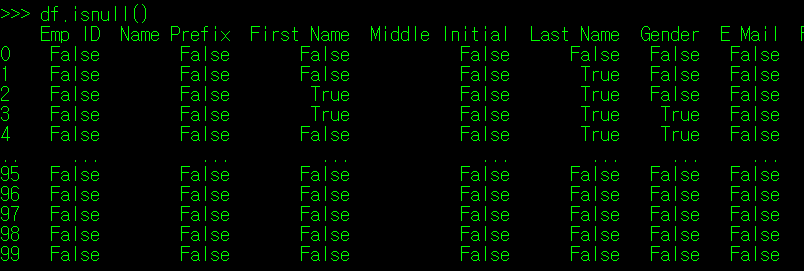
isnull()과 반대의 역할을 하는 notnull() 매서드도 존재한다. 이 매서드는 NaN이 아닌 값에 대해 True를 반환한다.

따라서 앞서 배웠던 검색 조건 필터를 DataFrame에 적용하는 경우, 결측치 값을 제외한 나머지 데이터만 추출할 수 있게 된다.
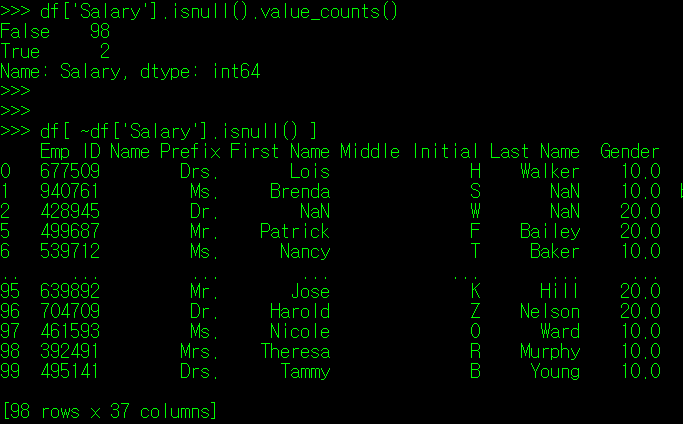
혹은 DataFrame에서 제공하는 dropna() 매서드를 사용하면 결측값 데이터가 포함된 Index나 Column을 제외할 수 있다. 이 매서드 내에 앞서 반복해서 보아왔던 axis 인자가 존재하는데, 기본값(0)일 경우 행을, 1일 경우 열을 제거한다.
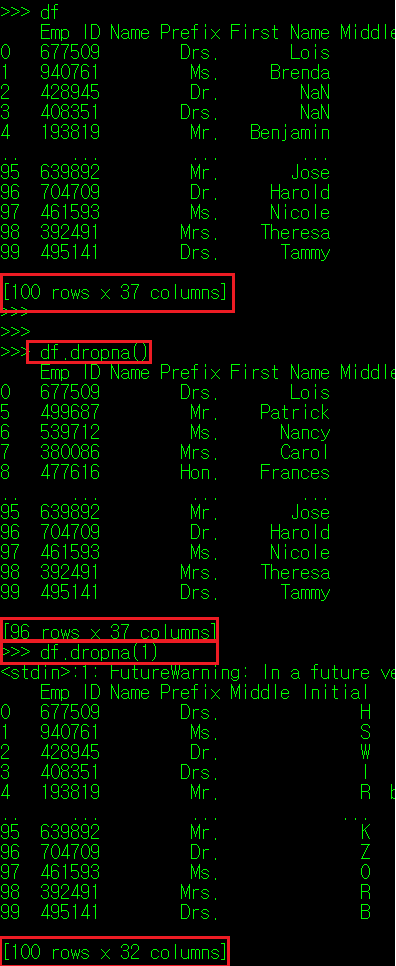
특정 Column에 결측치가 하나라도 포함된 Index를 제거하려면 DataFrame[["Column1", "Column2"...]].dropna()를 지정해주면 된다. DataFrame을 지정 Column만 추출한 결과를 토대로 동일한 기능을 수행하는 것이기 때문에 굳이 스크린샷을 달지는 않는다.
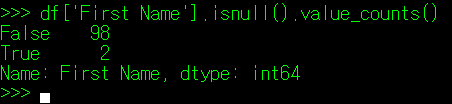
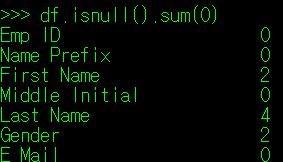
각 데이터 Index와 Column에서 결측치의 개수를 확인하는 방법은 아래와 같다. 위에서 보인 방식과 같이 value_counts() 매서드를 쓰거나, sum(axis) 매서드로 행과 열의 결측치 수를 확인하는 방법이 있다. value_counts()는 보통 특정 Column을 지정한 경우 많이 사용하며(True, False 등 Unique 값의 수를 표시하기 때문에), sum()의 경우 DataFrame 내에서 전체 행 또는 열의 결측치 수를 한 눈에 확인해야 할 때 사용한다.
[ value_counts() 매서드 ]
[ sum(0) 또는 sum(1) 매서드 ]
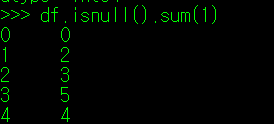
만약 데이터 분석 과정에서, 연봉정보가 빠진 Index 데이터는 잘못 수집(측정)된 데이터라고 가정한다고 하면, 위와 같이 결측치가 포함된 데이터를 제외한 DataFrame을 기준으로 분석 결과를 내면 된다. 하지만, 데이터 분석 과정에서 결측치 역시 이상치와 마찬가지로 전체 분석 결과에 지대한 영향을 미치기 때문에 결측치 데이터의 삭제보다 다른 값으로 대체하는 방식을 많이 사용한다.
(2) 결측치 데이터의 대체: interpolate(), fillna(), numpy.where()
결측치 데이터를 대체할 수 있는 방법은 여러가지가 있다. Column 값의 평균, 중위값 또는 이전/이후 Index의 Column 값을 사용하는 방법 등 여러가지다. 결측치를 대체하는 매서드는 크게 아래의 세 가지가 있다.
- interpolate()
- pandas.DataFrame.fillna()
- pandas.where()
interpolate()는 조선말로 보간법이라고 한다. 보간법은 실측치 사이 결측값이 존재하는 경우, 양 끝단의 실측치의 가운데 값을 사용한다. 만약 실측치 사이 3개의 결측값이 존재한다면 두 실측치의 1/4, 2/4, 3/4 값으로 대체된다.

pandas.DataFrame.fillna()는 말 그대로 NaN 결측값을 특정 값으로 채우겠다는 의미다. 따라서 fill() 매서드 인자로 대체할 값을 작성해주면 된다.
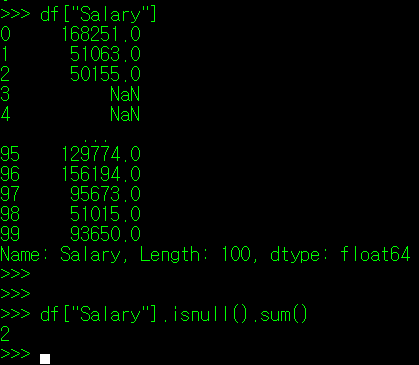
필자는 index 3, 4 번의 Salary 자료를 공란으로 만들었다. 이 자료가 결츠값이라 가정하고, 실측값 전체 Salary의 평균, 중위값으로 결측값을 대체한다고 가정해보자. 아래와 같이 진행할 수 있다.
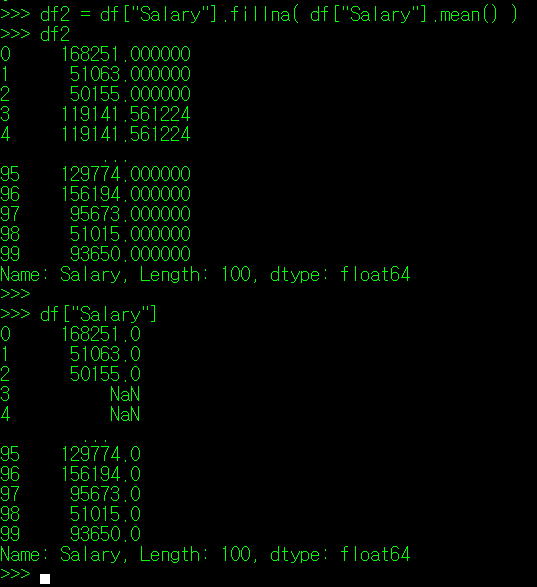
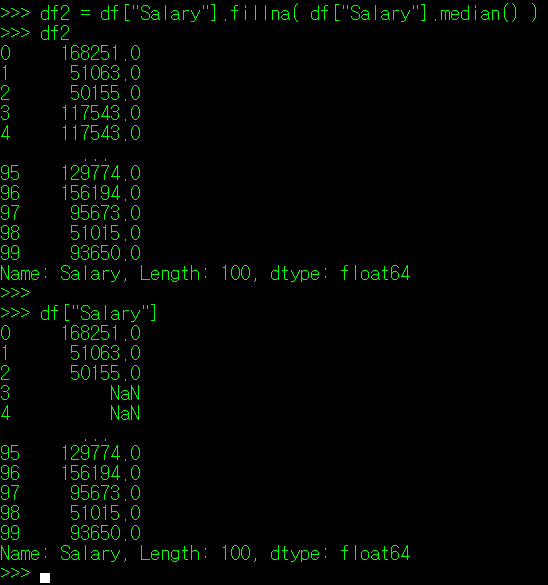
fillna() 매서드의 경우에도 inplace 인자를 True로 지정해야만 변경 내용이 기존 DataFrame에 반영된다.
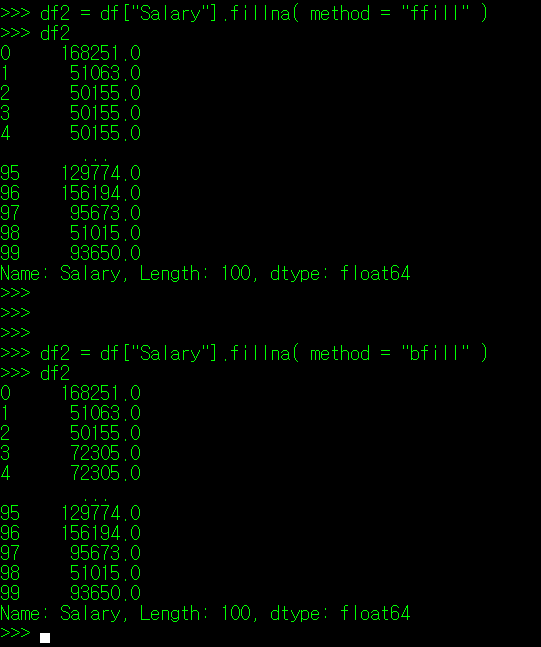
만약, 결측값 앞, 뒤의 값으로 대체를 하고 싶다면, fillna() 인자에 값을 지정하는 대신 method 인자를 사용하는 방법이 있다. method는 크게 'ffill'과 'bfill' 값을 사용할 수 있는데, ffill은 forward(이전)값을, bfill은 back(다음)값을 지정할 때 사용한다.
만약, 다수의 Column에 위치한 결측치를 Column 별로 지정해주고 싶다면 fillna() 인자로 {"Column명1": "대체값", "Column명2": "대체값2"...} 를 지정하면 된다.
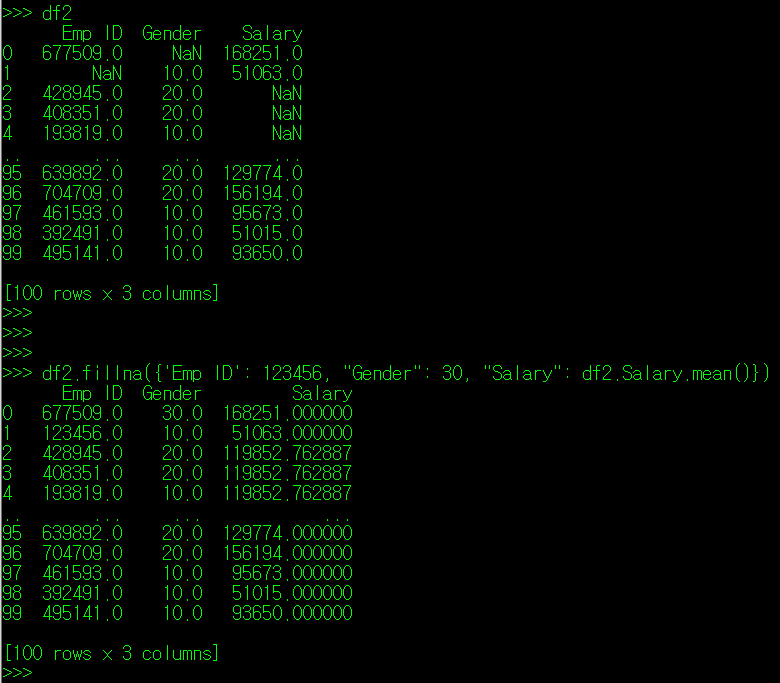
fillna() 매서드 외에 numpy 패키지 내에 있는 where 함수를 사용하여 결측치 값을 조건에 따라 다른 값을 부여하는 것도 가능하다. 실습을 위해 인적 사항에 대한 DataFrame 중, 앞 5명 중 일부의 First Name을 공란으로 바꾸고, 저장하자. 그리고 read_csv 호출 시, Emp ID, First Name, Last Name, Gender Column 만 불러오도록 코드를 짰다. 아래와 같이

이 값들 중 1~4 번 데이터는 First Name이 결측치로 나타난다. 필자는 각 Index의 Gender 값이 NaN인 값은 "결측치", 그렇지 않은 값은 "실측치"로 표시되도록 하려 한다.

위의 where() 매서드 내 조건 인자를 보면 알겠지만, NaN인 값에 대해서만 "결측치"가 표시되는 것을 확인할 수 있다. 만약 "실측치" 값을 원래 원본 데이터 값으로 유지하고 싶다면 다음과 같이 코드를 작성하면 된다.

사실 numpy.where() 매서드는 조건에 따른 분기에 대한 내용이 반드시 명시되어야 하기 때문에 잘 사용하는 매서드는 아니다.
(3) 함수를 이용한 데이터의 대체
이번에는 함수 적용 매서드를 사용하여 결측값을 대체하는 방법에 대해 알아보자.
다시, 인적사항의 원본 데이터로부터 필자가 다음과 같이 Emp ID, Salary, Gender 정보만 뽑았다고 가정해보자.
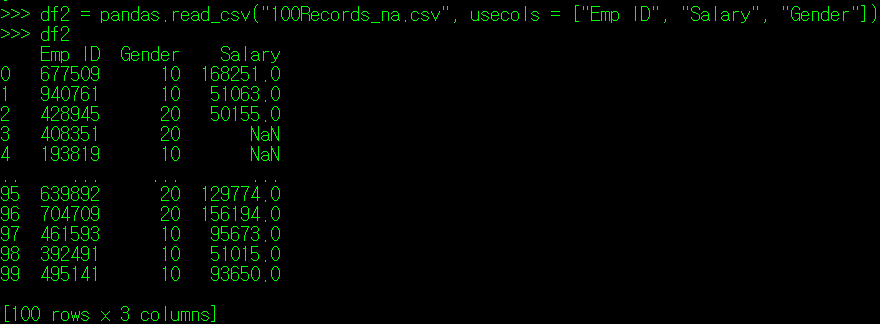
위쪽의 3, 4번 Index를 보면 Salary 값이 결측치로 나타난다. 이 값을 전체 Salary의 평균이 아니라 이들 Index가 속해있는 Gender의 평균으로 넣어주는 방법은 없을까? 즉, 3번 Index의 직원은 결측 연봉값으로 여성 직원(20)의 평균 연봉을, 4번 index의 직원은 남성 직원(10)의 평균 연봉 값을 넣어주는 것이다.
이를 위해, 우리는 County 별 평균 연봉을 알아야 한다. 먼저 df2에 groupby() 매서드로 Gender 값에 따른 데이터로 변환되도록 만들어보자. groupby()의 인자는 Column명이 들어가는데, 이 컬럼의 값이 명목척도로 구성되어야 한다.

위의 데이터를 보면 좌측의 index 명으로 Gender의 Unique() 를 구성하는 값인 10과 20이 보이며, 이들의 ["Salary"]에 대한 describe() 정보가 출력됨을 확인할 수 있다. 정확한 남/여 직원의 평균 연봉값은 아래와 같이 변수화해주자.

다음으로, Gender 값에 따른 대체 값을 Tuple로 지정해주어야 한다. 남성에 대해서는 salary_mean_mail값을, 여성에 대해서는 salary_mean_female 값을 적용할 것이기 때문에 아래와 같이 Tuple 변수를 하나 생성한다.

이제, df2를 groupby("Gender")로 묶은 DataFrame이 어떤 형태로 출력되는지 알아보자. 아래와 같이 apply() 매서드 인자로 lambda 식을 작성하고 df2.groupby("Gender") 값이 어떻게 나오는지 확인해보자.
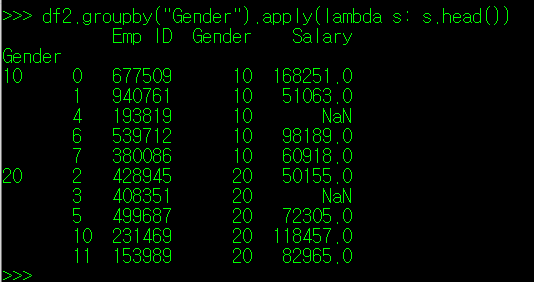
s 값은 df2.groupby("Gender")로 분류된 2개의 DataFrame 각각을 의미한다. 따라서 print(s)를 lambda 식에 적용하면 Gender 10, 20으로 구분된 2 개의 DataFrame이 생성되는 것을 확인할 수 있다. 각각의 DataFrame의 Gender 값은 name이라는 객체명으로 출력이 가능하다.

그럼, groupby() 매서드로 성별에 따른 Salary 정보만 출력해보자.
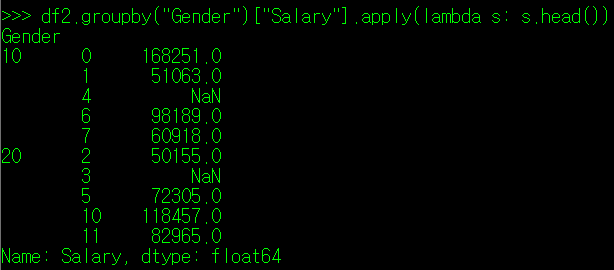
여기까지 출력이 되었다면, 우리는 lambda 식을 통해, Salary의 결측치의 숫자를 확인하거나 결측치를 다른 값으로 대체할 수 있게 된다. 대체를 하는 매서드인 fillna()를 사용하되, 인자에 아까 만들어주었던 tuple 값인 fillna_replacement를 적용해주자. 아래와 같이.

'Python > Python DataAnalysis' 카테고리의 다른 글
| [Python Data Analysis] 12. pandas 데이터 전처리 - 정규화 (0) | 2021.12.22 |
|---|---|
| [Python Data Analysis] 11. 데이터 분석 절차 (0) | 2021.12.12 |
| [Python Data Analysis] 9. DataFrame 데이터 조건 검색 및 수정 (0) | 2021.11.20 |
| [Python Data Analysis] 8. DataFrame 데이터 슬라이싱 (0) | 2021.11.17 |
| [Python Data Analysis] 7. DataFrame 데이터 정보 확인 및 기본 통계 (0) | 2021.11.14 |




댓글